本文试图通过引入更多基础知识和辅助信息,来深入理解MLA。
原标题:DeepSeek技术解读1:彻底理解MLA
文章来源:智猩猩GenAI
内容字数:14558字
DeepSeek MLA: 极致模型优化与高效推理
本文解读DeepSeek提出的MLA(Multi-Head Latent Attention)技术,该技术通过优化KV-cache来减少显存占用,从而提升LLM推理性能。文章从LLM推理过程、显存使用情况、KV-cache优化方法以及MLA原理四个方面展开,深入剖析MLA的技术细节。
1. LLM推理过程及性能瓶颈
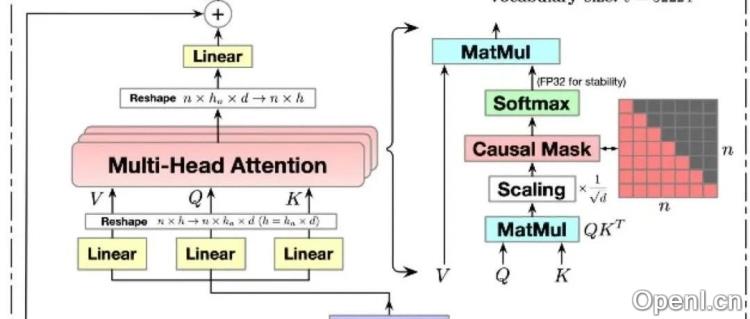
LLM推理分为prefill阶段(一次性计算所有Prompt tokens)和decode阶段(每次生成一个token)。核心计算消耗在Transformer的MHA(多头注意力机制)上。为了加速,主流方法采用KV-cache缓存前序token的K、V矩阵,避免重复计算。但大型LLM的KV-cache占用大量显存,导致访存成为瓶颈,影响推理速度。不同存储介质(HBM、SRAM、DRAM)的访问速度差异巨大,推理阶段主要依赖HBM(显存)。
2. LLM推理阶段显存使用情况
推理阶段显存主要用于存储模型参数、KV-cache和运行时中间数据。模型参数大小固定,而KV-cache大小随batch size和序列长度动态变化。一个token的KV-cache存储量巨大,例如Qwen-72B模型,单token需缓存约10KB数据。大batch size和长序列会显著增加KV-cache占用,从而导致需要更多GPU卡才能完成推理。
3. KV-cache优化方法
现有KV-cache优化方法主要包括共享KV(如MQA、GQA)、窗口KV、量化压缩和计算优化。其中,共享KV方法通过多个Head共享K、V来减少存储,MQA所有Head共享一个KV,GQA将Head分组共享KV。
4. MLA原理详解
MLA是一种共享KV的变体,它通过低秩矩阵分解压缩K、V的维度,并结合RoPE位置编码。MLA先对K、V进行低秩压缩,再通过变换矩阵恢复到原维度。同时,它在低维度下使用MQA方式计算包含RoPE的位置编码信息,并将低秩压缩后的向量和包含RoPE信息的向量拼接,最终实现KV-cache的压缩。通过“矩阵吸收”技术,MLA能够减少实际需要缓存的数据量,从而降低显存占用。
5. MLA与其他方法对比
与MQA、GQA相比,MLA虽然缓存的Latent KV较短,但其恢复全K、V的能力更强,特征表达能力也更优,实现了性能和效率的兼顾。
6. 总结
MLA通过巧妙的低秩分解和RoPE位置编码的融合,有效压缩了KV-cache,在不显著降低模型效果的情况下,大幅提升了LLM的推理性能。该技术体现了DeepSeek在模型细节优化和工程能力上的深厚积累。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。