MTP技术详解。
原标题:DeepSeek技术解读2:如何一次性预测多个token
文章来源:智猩猩GenAI
内容字数:13842字
DeepSeek-V3 的MTP方法详解
本文详细解读了DeepSeek-V3中的多标记预测(MTP)方法,并将其与其他类似工作进行比较。文章从动机、方法探索和DeepSeek-V3的具体实现三个方面展开,并对MTP在训练和推理阶段的应用进行了深入分析。
1. MTP方法的动机
当前主流的大型语言模型(LLMs)采用解码器-基础模型结构,以token-by-token的方式进行序列生成。这种方式导致频繁的访存交互,成为训练和推理的瓶颈。MTP方法的核心思想是将1-token的生成转变为multi-token的生成,从而提升训练和推理效率。在训练阶段,一次生成多个token可以提高样本利用效率,加速模型收敛;在推理阶段,一次生成多个token可以显著提升推理速度。
2. MTP方法的探索
文章回顾了MTP方法的演进过程,重点介绍了Google在2018年提出的Blockwise Parallel Decoding和Meta在2024年提出的MTP方法。Blockwise Parallel Decoding主要关注推理阶段的加速,通过并行预测多个token并进行验证来提高效率。Meta的MTP方法则更注重训练阶段的优化,通过一次预测多个token来学习更长的依赖关系,并提高样本利用效率。
3. DeepSeek MTP方法的实现
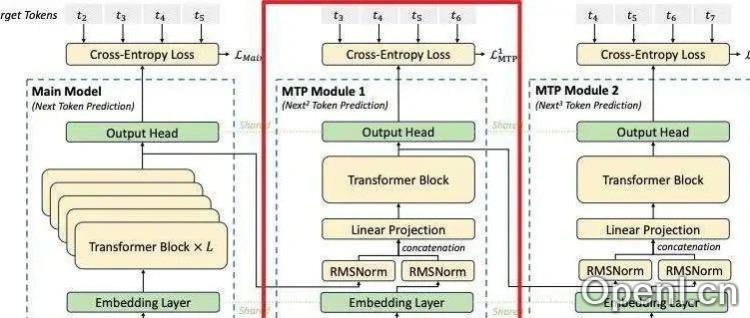
DeepSeek-V3的MTP方法在结构上更加复杂,它采用多个顺序模块(Module)来预测多个token,并保留了序列推理的因果链关系。每个模块包含共享的embedding层、Transformer层和输出头。DeepSeek V3利用Teacher forcing模式进行训练,在推理阶段则可以使用self-speculative decoding来提高效率。
4. DeepSeek MTP的训练与推理
DeepSeek V3 的MTP模块在训练阶段通过交叉熵损失函数计算每个预测头的损失,并通过对多个token的预测来提高样本利用率,从而加速模型收敛。推理阶段则可以采用两种方法:一是移除MTP模块,直接使用主模型进行token-by-token预测;二是保留MTP模块,进行self-speculative decoding,利用多个预测头并行生成token,提高推理速度。
5. 总结
本文对DeepSeek-V3的MTP方法进行了详细的解读,并与其他相关工作进行了比较。文章通过图示和公式对MTP的网络结构、训练过程和推理过程进行了清晰的阐述,为读者理解MTP方法提供了有益的参考。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,专注于生成式人工智能。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。