首个公开发布release模型并分享成功方法和失败尝试的报告
原标题:推理模型的GPT 2时刻!DeepSeek-R1技术解读
文章来源:智猩猩GenAI
内容字数:5303字
DeepSeek-R1: Reasoning LLM的GPT-2时刻
本文总结了知乎文章《DeepSeek-R1: Reasoning LLM的GPT-2时刻》的核心内容,该文章介绍了DeepSeek-R1模型的训练方法,并讨论了相关尝试和未来方向。
1. DeepSeek-R1 模型概述
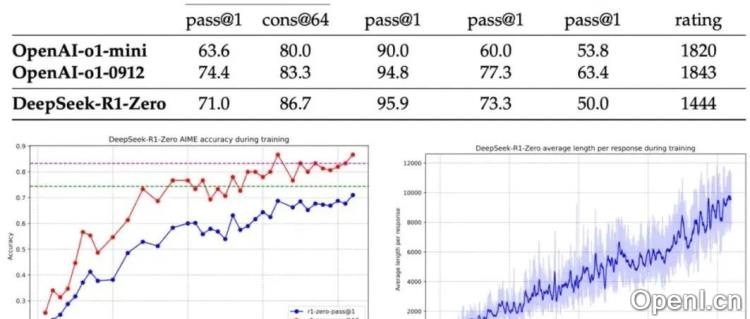
DeepSeek-R1是一个强大的推理大型语言模型,其核心在于结合了简单的强化学习算法(GRPO)和精确的奖励信号(类似Tulu3的RLVF),无需复杂的蒙特卡洛树搜索(MCTS)或规划图(PRM)。文章介绍了两种训练模型:R1-zero和R1。
2. R1-zero: 纯强化学习训练
R1-zero直接基于基础模型进行强化学习训练,无需中间的监督微调(SFT)阶段。它利用基于规则的奖励机制(Rule-based RM),通过prompt引导模型在“和“标签之间输出推理过程,并在“和“标签之间输出最终答案。奖励信号的设计非常关键,例如数学题的答案以特定格式输出,代码题则通过编译器反馈进行验证。
3. R1: 多阶段训练
R1-zero存在推理过程可读性差以及混合语言输出的问题。因此,R1采用多阶段训练流程来解决这些问题:
- 冷启动阶段:利用少量高质量的人工标注数据进行冷启动,提高推理过程的可读性。
- 推理导向强化学习阶段:专注于提升模型在数学、代码、科学和逻辑推理等任务上的性能,并引入语言一致性奖励来解决混合语言输出的问题。
- 拒绝采样+监督微调阶段:收集大量数据,包括推理数据和通用领域数据。推理数据采用拒绝采样方法,过滤掉可读性差的数据;通用领域数据则部分采用DeepSeek-V3进行数据增强。
- 全场景强化学习阶段:进一步对齐人类偏好,提升模型的帮助性和无害性,并细化推理能力。
4. 失败的尝试
文章也总结了几个失败的尝试,包括PRM和MCTS。PRM难以明确定义步骤并评估其准确性,且存在奖励作弊问题;MCTS由于LLM的token空间巨大,难以扩展。
5. 讨论与展望
文章最后提出了几个疑问和未来的研究方向:
- R1-zero的成功是否依赖于强大的预训练模型?
- 如何设计更好的初始prompt和RL训练数据?
- GRPO的具体设置参数?
- 其他强化学习算法(如PPO、Reinforce)是否更有效?
- 如何为物理、化学等领域设计精确的奖励信号?
- MCTS在LLM上能否取得突破?
总而言之,DeepSeek-R1证明了基于规则的奖励机制和简单的强化学习算法能够有效提升LLM的推理能力,为Reasoning LLM的研究提供了新的方向。然而,该方法仍有许多改进空间,未来的研究将进一步探索更有效的训练方法和更广泛的应用场景。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,专注于生成式人工智能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。