VideoWorld:基于未标注视频数据训练的自回归视频生成模型
原标题:字节提出VideoWorld,从自回归视频生成模型获取世界知识!
文章来源:智猩猩GenAI
内容字数:10972字
VideoWorld: 从未标记视频中学习知识
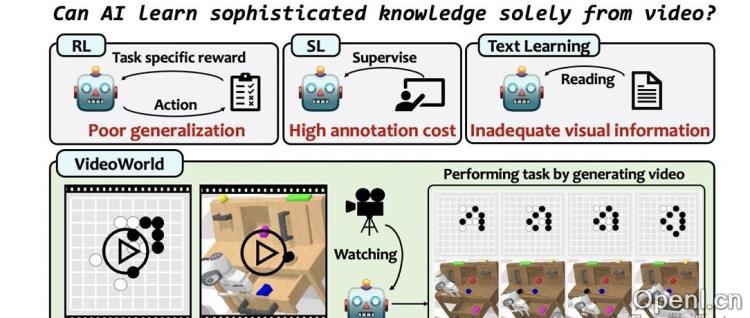
本文介绍了VideoWorld,一个基于未标记视频数据训练的自回归视频生成模型,它能够仅从视觉输入中学习复杂知识,例如规则、推理和规划能力。这项研究挑战了当前主要依赖文本数据的大型语言模型范式,并探索了视觉信息在知识学习中的重要性。
1. 研究动机与背景
大型语言模型(LLMs)通过“下一个标记预测”范式学习了显著的世界知识,但其知识获取主要依赖于文本数据,无法完全捕捉所有形式的知识或涵盖现实世界中的大量信息。生物体,特别是灵长类动物,主要通过视觉信息学习,这启发了研究者探索深度生成模型是否能够仅从视觉输入中学习复杂知识。
2. VideoWorld 模型架构
VideoWorld采用了一个基于自回归视频生成器的框架,包含VQ-VAE编码器-解码器和一个自回归Transformer。为了提高学习效率,VideoWorld的核心组件是潜在动态模型(LDM)。LDM通过压缩每一帧到其后续帧的视觉变化为一组潜在代码,从而实现视觉变化的紧凑表示,这对于长期推理和规划任务至关重要。LDM的输出与自回归Transformer无缝集成,共同生成视频帧并进行任务操作。
3. 关键技术:潜在动态模型 (LDM)
LDM旨在解决原始视频数据冗余的问题。通过使用查询嵌入表示跨多个帧的视觉变化,LDM将丰富的视觉信息压缩为紧凑的嵌入,提高了学习效率。实验结果表明,LDM显著提高了模型的性能和学习速度,尤其是在需要长期推理和规划的任务中。
4. 实验结果与分析
VideoWorld在三个基准测试上进行了评估:Video-GoBench、CALVIN和RLBench。
- Video-GoBench (围棋): VideoWorld在该基准测试中达到了5段专业水平,超过了基于强化学习的KataGo模型,证明了其在掌握复杂游戏规则和策略方面的能力。即使是参数规模最小的模型也表现出色,并且性能随着模型规模的增加而持续提高。
- CALVIN (机器人控制): VideoWorld有效地学习了多样化的控制操作,并在不同环境中进行了泛化,接近了使用真实动作标签监督的模型的性能,这表明LDM有效地支持了基于视频的知识学习。
- RLBench (机器人控制): VideoWorld在RLBench中也表现出良好的泛化能力,在不同的机器人环境中成功完成了任务,接近Oracle模型的性能,这展示了其作为通用知识学习者的潜力。
实验结果验证了两个关键发现:(1)模型可以仅从原始视频中学习基本知识;(2)视觉变化的表示对于知识学习至关重要。
5. 结论
VideoWorld成功地从未标记视频数据中学习了复杂知识,证明了基于视频的知识学习的可行性。潜在动态模型的引入显著提高了学习效率和效果。这项研究为从视觉数据中获取知识开辟了新的途径,并为未来构建能够在现实世界中思考和行动的人工智能系统奠定了基础。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。