JoyGen – 京东和港大推出音频驱动的3D说话人脸视频生成框架
JoyGen是什么
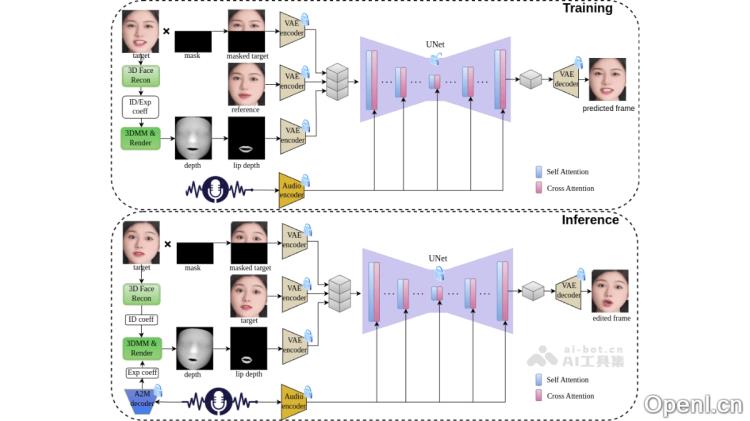
JoyGen是由京东科技与香港大学共同开发的一种音频驱动的3D人脸视频生成框架,旨在实现同步的唇部动作与音频内容,并提供卓越的视觉效果。该系统结合音频特征与面部深度图,生成与音频完美匹配的唇部,并采用单步UNet架构进行高效的视频编辑。JoyGen通过使用包含130小时中文视频的高质量数据集进行训练,并在开源的HDTF数据集上验证了其卓越性能。实验结果显示,JoyGen在唇部与音频的同步性及视觉质量方面达到了行业领先水平,为说话人脸视频的编辑提供了创新的技术解决方案。
JoyGen的主要功能
- 唇部与音频精准同步:通过音频驱动的技术,确保视频中人物的唇部动作与音频内容高度一致。
- 卓越的视觉效果:生成的视频展现逼真的视觉效果,包括自然的面部表情和细致的唇部细节。
- 视频编辑与提升:可在现有视频基础上进行唇部的编辑和优化,无需重新制作整个视频。
- 多语言支持:能够支持中文、英文等多种语言的视频生成,适用于多样化的应用场景。
JoyGen的技术原理
- 第一阶段:
- 音频驱动唇部生成的3D重建模型:该模型从输入的面部图像中提取身份系数,以描述人物的面部特征。
- 音频到模型:将音频信号转换为表情系数,以控制唇部的。
- 深度图生成:结合身份系数和表情系数生成面部3D网格,利用可微渲染技术生成面部深度图,为后续视频合成提供支持。
- 第二阶段:
- 视觉外观合成与单步UNet架构:使用单步UNet网络将音频特征和深度图信息融合到视频帧生成过程中,通过编码器将输入图像映射到低维潜在空间,并结合音频特征和深度图进行唇部的生成。
- 跨注意力机制:音频特征通过跨注意力机制与图像特征交互,确保生成的唇部动作与音频信号高度一致。
- 解码与优化:生成的潜在表示通过解码器还原为图像空间,最终形成视频帧。基于L1损失函数在潜在空间与像素空间进行优化,确保生成视频的高质量与同步性。
- 数据集支持:JoyGen使用包含130小时中文视频的高质量数据集进行训练,确保模型适应各种场景与语言环境。
JoyGen的项目地址
- 项目官网:https://joy-mm.github.io/JoyGen/
- GitHub仓库:https://github.com/JOY-MM/JoyGen
- arXiv技术论文:https://arxiv.org/pdf/2501.01798
JoyGen的应用场景
- 虚拟主播与直播:创造虚拟主播,实现新闻播报、电商直播等,根据输入音频实时生成自然的唇部动作,提升观众体验。
- 动画制作:在动画影视领域,快速生成与配音同步的唇部动画,减轻动画师的工作负担,提高制作效率。
- 在线教育:生成虚拟教师形象,实现与教学语音同步的唇部动作,使教学视频更加生动,增强学生学习兴趣。
- 视频内容创作:帮助创作者快速生成高质量说话人脸视频,如虚拟人物短剧、搞笑视频等,丰富创作形式。
- 多语言视频生成:支持多语言,将一种语言的视频快速转换为其他语言版本,确保唇部动作与新语言音频同步,便于内容的国际化传播。
常见问题
- JoyGen支持哪些语言?:JoyGen支持中文、英文等多种语言的视频生成,适应多样化需求。
- 如何访问JoyGen的项目资料?:您可以通过访问项目官网或其GitHub仓库获取详细资料和技术文档。
- JoyGen的主要应用领域是什么?:JoyGen可广泛应用于虚拟主播、动画制作、在线教育、视频创作等多个领域。
- JoyGen的技术原理是什么?:JoyGen结合音频特征与面部深度图,通过先进的深度学习模型生成与音频一致的唇部。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。