LLMDet – 阿里通义联合中山大学等机构推出的开放词汇目标检测模型
LLMDet是由阿里巴巴集团通义实验室、中山大学计算机科学与工程学院、鹏城实验室等机构联合推出的一款开放词汇目标检测器。它通过与大型语言模型(LLM)的协同训练,显著提升了目标检测的性能。LLMDet利用GroundingCap-1M数据集,结合图像、定位标签和详尽的图像描述,生成丰富的视觉特征,并通过标准的定位损失和描述生成损失进行训练。其在多个基准测试中展现出卓越的零样本检测能力,作为强大的视觉基础模型,LLMDet能够进一步支持构建更先进的多模态模型,实现与LLM之间的互利共赢。
LLMDet是什么
LLMDet是一款由阿里巴巴集团通义实验室、中山大学计算机科学与工程学院以及鹏城实验室等机构联合开发的开放词汇目标检测系统。该系统通过与大型语言模型(LLM)的协同训练,显著提高了目标检测的效果。LLMDet可以构建一个包含图像、定位标签和详细图像描述的数据集(GroundingCap-1M),并利用LLM生成的长描述来丰富视觉特征。其训练过程基于标准的定位损失和描述生成损失。LLMDet在多个基准测试中展现了出色的零样本检测能力,作为一种强大的视觉基础模型,有助于构建更为强大的多模态模型,实现与LLM的双赢。
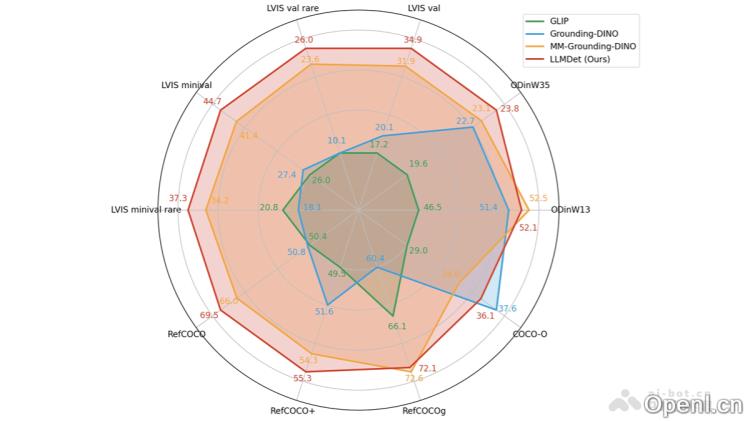
LLMDet的主要功能
- 开放词汇检测:LLMDet能够识别训练阶段未见过的任何类别目标,通过文本标签与视觉特征的对齐,实现新类别的识别。
- 零样本迁移能力:在没有目标类别标记的情况下,LLMDet可以直接迁移到新的数据集进行检测,展现出极强的泛化能力。
- 图像理解与描述生成:该系统能够生成详细的图像描述,包含丰富的细节信息,如对象类型、纹理、颜色和动作等,帮助模型更好地理解图像内容。
- 提升多模态模型性能:作为一个视觉基础模型,LLMDet与大型语言模型结合,助力构建更强大的多模态模型,提升视觉问答、图像描述等任务的表现。
LLMDet的技术原理
- 数据集构建:LLMDet基于GroundingCap-1M数据集,每张图像都配有定位标签和详细描述,丰富的描述有助于模型更好地理解图像中的对象及其关系。
- 模型架构:该系统由标准的开放词汇目标检测器与LLM组成,检测器负责提取图像特征并定位目标,LLM则利用这些特征生成详细的图像描述和区域级短语。
- 协同训练:LLMDet通过两个阶段的训练实现与LLM的协同优化,首先训练投影器将检测器的特征映射到LLM的输入空间,随后将检测器、投影器和LLM作为整体进行微调,训练目标包括标准的定位损失和描述生成损失。
- 多任务学习:LLMDet引入图像级和区域级的描述生成任务,通过生成详细的描述来丰富视觉特征,提升模型对图像的整体理解能力。多任务学习方式有效提高了检测性能,增强了模型的开放词汇能力。
LLMDet的项目地址
- GitHub仓库:https://github.com/iSEE-Laboratory/LLMDet
- arXiv技术论文:https://arxiv.org/pdf/2501.18954
LLMDet的应用场景
- 智能安防:实时监测摄像头画面中的异常目标或行为,具备强大的适应性,无需额外训练。
- 自动驾驶:帮助车辆识别道路上的各类障碍物和未见过的场景,从而提升安全性和可靠性。
- 图像内容审核:自动对图像内容进行审核,识别违规或不当内容,提高审核效率。
- 智能相册管理:自动对照片进行分类和标注,方便用户搜索和管理,支持多种未见过的类别。
- 医疗影像分析:对医学影像进行分析,快速识别异常区域,降低对大量标注数据的需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。