ACE++ – 阿里通义推出的升级版图像生成与编辑模型
ACE++是什么
ACE++是由阿里巴巴通义实验室开发的一款前沿图像生成与编辑工具,利用指令化和上下文感知的内容填充技术,实现高品质的图像创作与编辑功能。该工具提供多种模型,针对不同任务进行优化:ACE++ Portrait专注于生成一致的人物肖像;ACE++ Subject确保在多种场景下的主题一致性;ACE++ LocalEditing则允许用户重新绘制图像的特定区域,同时保留原有的结构。即将推出的ACE++ Fully将支持更多指令化编辑和参考生成任务。
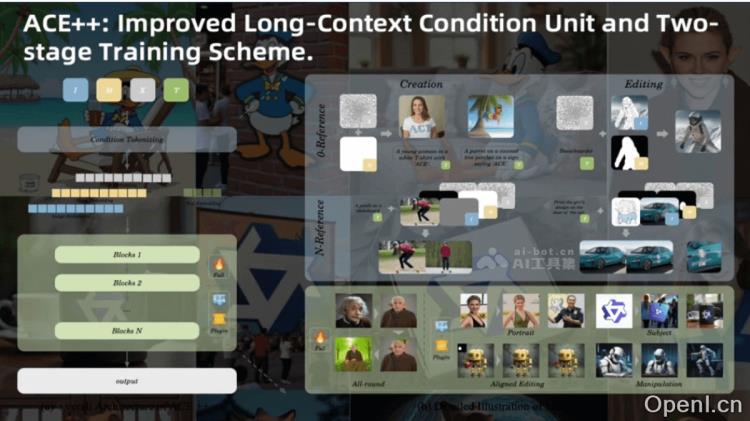
ACE++的主要功能
- 图像生成
- 肖像生成:通过ACE++ Portrait模型,用户可以根据输入的指令生成高质量的肖像,确保面部特征和风格的一致性。
- 主题生成:利用ACE++ Subject模型,用户能够在不同的背景下生成具有特定主题的图像,如将某个标志物放置于多样的场景中。
- 图像编辑
- 局部编辑:ACE++ LocalEditing模型允许用户对图像特定区域进行修改,同时保留整体的结构和风格。例如,可以调整人物的服装、背景或特定物体的外观。
- 风格化编辑:用户可以通过简单的指令对图像进行风格转换,如将普通照片转化为艺术风格或特定的视觉效果。
- 上下文感知内容填充:根据图像上下文智能填充缺失或需修改的部分,确保生成图像在视觉上自然且和谐。
- 指令驱动的交互:用户可以通过自然语言指令轻松控制图像的生成和编辑过程,例如指定生成特定风格的人物肖像或要求在图像中添加、删除或修改某个元素。
- 多任务支持:ACE++支持多种图像处理任务,包括但不限于:
- 虚拟试穿:借助ACE++ Subject模型实现虚拟试穿效果。
- 标志粘贴:将品牌标志或元素嵌入到不同物品或场景中。
- 照片修复:对损坏或模糊的照片进行修复和增强。
- 电影海报编辑:生成或修改电影海报,确保人物和场景的一致性。
ACE++的技术基础
- 改进的长上下文条件单元(LCU++):ACE++引入了LCU++输入范式,通过在通道维度拼接输入图像、掩码和噪声,形成条件单元(CU)特征图。这种新方法减少了上下文感知框架的干扰,降低了模型适应的成本。LCU++输入格式能够扩展到无参考图像(0-ref)和多参考图像(N-ref)任务,增强了模型的适应性。
- 两阶段训练方案:ACE++采用两阶段的训练策略。第一阶段,模型基于文本到图像的生成模型进行预训练,专注于0-ref任务,快速适应条件输入。第二阶段,模型在所有数据上进行微调,旨在支持通用指令并优化模型对输入参考图像的重建能力和目标图像的生成能力。
- 模型架构:ACE++整体架构结合了LCU++范式,通过x-embed层将CU特征图映射为序列化标记,用作Transformer层的输入。模型训练的目标是最小化预测速度与真实速度之间的均方误差,赋予模型上下文感知的生成能力。
- 任务支持与模型优化:ACE++提供了一套工具,支持多种图像编辑和生成任务,如肖像一致性、主题一致性和局部编辑等。针对常见应用场景,ACE++训练了轻量级的领域稳定微调模型,如LoRA策略,以提升模型在特定任务中的表现。
ACE++的项目地址
- 项目官网:https://ali-vilab.github.io/ACE_plus
- Github仓库:https://github.com/ali-vilab/ACE_plus
- HuggingFace模型库:https://huggingface.co/ali-vilab/ACE_Plus
- arXiv技术论文:https://arxiv.org/pdf/2501.02487
ACE++的应用场景
- 虚拟试穿:通过ACE++ Subject模型,用户能够将服装或配饰放置于不同人物模型上,创造虚拟试穿的效果。这项功能帮助设计师快速评估设计效果,也为电商平台提供个性化的试穿体验。
- 品牌标志粘贴:在产品设计和广告制作过程中,ACE++ Subject模型可以将品牌标志或设计元素嵌入到多种背景或物品上。
- 照片编辑:ACE++支持对现有照片进行全方位的编辑操作,包括风格转换、元素增减、背景替换等。
- 电影海报编辑:利用ACE++ Portrait模型,用户可以对电影海报中的人物肖像进行风格化处理或修改,调整表情和服装风格,确保海报满足多样化的宣传需求。
- 局部编辑:ACE++ LocalEditing模型能够对图像中特定区域进行重新绘制,同时保持整体结构和风格,适用于修复照片中的划痕和污渍,或美化人物的某个部位。
- 艺术创作与设计:艺术家和设计师可以利用ACE++的生成和编辑功能,轻松实现创意。根据文字描述生成初步设计草图,或对已有设计进行风格化修改,从而提升创作效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。