文章从模型架构和推理系统两个方面展开,主要关注与推理有关的内容。
原标题:DeepSeek-V3推理系统分析
文章来源:智猩猩GenAI
内容字数:13895字
DeepSeek-V3推理系统深度解读
本文对DeepSeek-V3推理系统进行了深入分析,主要从模型架构和推理系统两个方面展开,重点关注推理相关内容。DeepSeek-V3是一个拥有671B参数的巨型语言模型,其推理系统的规模和复杂度都令人印象深刻。
1. 模型架构
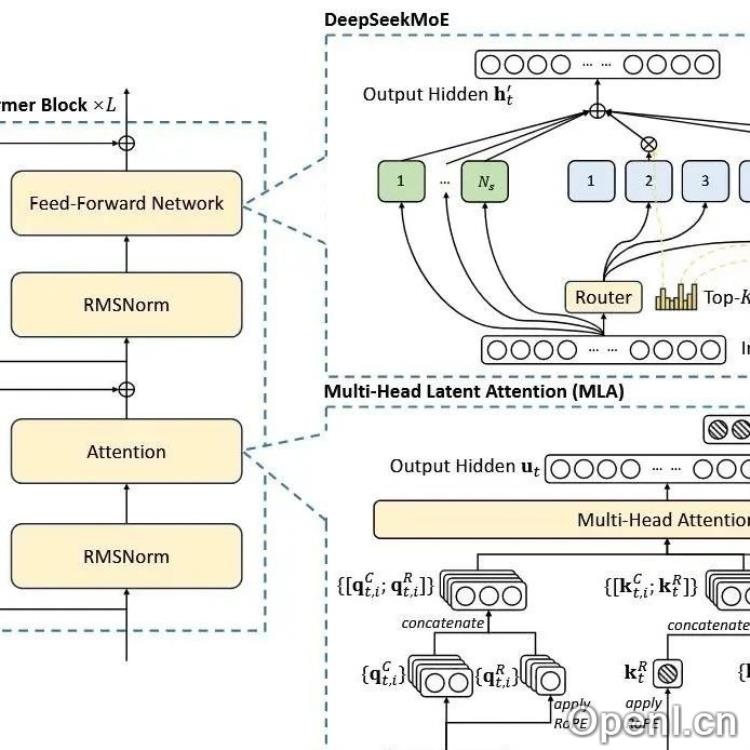
- MLA (Multi-head Latent Attention): DeepSeek-V3采用MLA注意力机制,通过压缩latent KV来减少KV Cache的内存占用,从而容纳更大的batch size。MLA相比MHA、GQA、MQA拥有更强的表达能力,并且通过矩阵吸收技术进一步减少显存占用和访存量,尤其在解码阶段效果显著。但矩阵吸收在预填充阶段可能增加计算量,并且与张量并行(TP)的兼容性较差。
- DeepSeek MoE: 采用细粒度专家(256个routed experts和top-8 routing),比V2版本更多,并使用sigmoid函数计算路由分数,与传统MoE模型有所不同。
- MTP (Multi-Token Prediction): MTP模块可以额外预测多个token,提升训练效果,在推理阶段开启投机采样可加速1.8倍。
- 模型架构对推理系统的影响: MLA减小KV Cache,提升attention计算速度;MTP加速解码;DeepSeek MoE的稀疏设计易造成资源浪费,并对负载均衡提出挑战。
2. 推理系统
- 计算集群: 使用NVIDIA H800 GPU,单节点8卡,节点内NVLink互联,节点间IB互联。
- PD分离: 将预填充(Prefilling)和解码(Decoding)阶段分开部署,采用不同的并行策略。预填充阶段最小单元为32卡,解码阶段最小单元为320卡,规模巨大。
- 并行策略: 采用数据并行(DP)、张量并行(TP)和专家并行(EP)。解码阶段DP规模高达80-way,充分利用全局batch size,提高每个expert处理的token数量。EP规模也极大,解码阶段每张卡只放置一个expert。
- 负载均衡: 预填充阶段使用冗余专家和动态冗余策略;解码阶段每张卡只持有1个专家,剩余GPU存放冗余专家和共享专家。共享专家被视为负载很大的routed expert,这增加了通信量,但通过巧妙的设计,可以使其与all-to-all通信重叠执行,提高效率。
- Pipeline: 使用2个microbatch的pipeline,将通信算子和memory-bound算子与计算密集型算子重叠执行,最大化硬件利用率。解码阶段的pipeline设计尤为精巧,通过精细的SM分配,充分利用硬件资源。
- 推理系统总结: PD分离减少干扰;解码实例超大规模利用超大聚合带宽;Pipeline是高吞吐的关键;系统设计复杂,需要精细的profile和实验。
DeepSeek-V3的推理系统是一个高度优化的复杂系统,其设计理念和技术细节都值得深入研究。通过PD分离、超大规模并行、Pipeline以及精细的负载均衡策略,DeepSeek-V3实现了高效的巨型语言模型推理。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下账号,专注于生成式人工智能,主要分享技术文章、论文成果与产品信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。