`ParentDocumentRetriever` 通过 **分层检索** 方式,解决了传统向量搜索容易导致的上下文缺失问题。\x0d\x0a\x0d\x0a它特别适用于长文档处理,能够提高问答系统的检索质量。
原标题:LangChain实战 | ParentDocumentRetriever 优化长文档的向量搜索质量
文章来源:AI取经路
内容字数:6039字
ParentDocumentRetriever:解决长文档检索上下文缺失的利器
在构建基于大语言模型(LLM)的问答系统时,高效准确的信息检索至关重要。然而,传统的向量搜索方法常常面临上下文缺失的难题,影响最终答案的完整性和准确性。本文将深入探讨LangChain提供的ParentDocumentRetriever,一种能够有效解决此问题的分层检索技术。
1. 传统向量搜索的局限性
传统的向量搜索通常将文档分割成较小的片段,然后根据相似度匹配用户查询。这种方法虽然能快速找到与查询相关的片段,但往往只返回局部信息,缺乏完整的上下文。例如,从一篇长文中检索某个特定概念,传统方法可能只返回包含该概念的单个句子或段落,而忽略了前后文对其理解至关重要的信息,导致答案支离破碎,难以理解。
2. ParentDocumentRetriever的核心原理
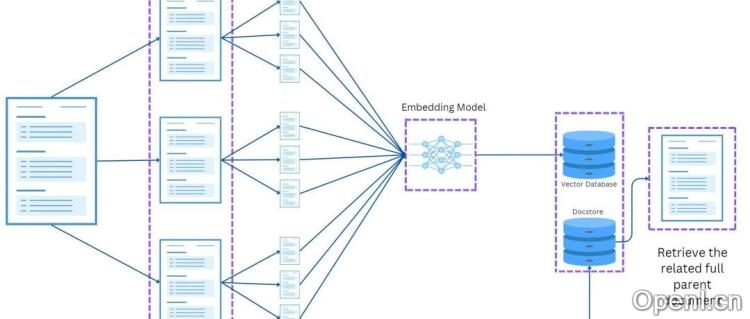
ParentDocumentRetriever巧妙地解决了这个问题。它采用了一种分层检索策略,将长文档首先分割成较大的“父文档”(Parent Documents),再将父文档进一步分割成较小的“子文档”(Child Documents)。子文档的嵌入向量存储在向量数据库中,用于快速检索。
当用户提出查询时,系统首先在子文档中进行相似度搜索,找到最匹配的子文档。然后,系统根据子文档找到其所属的父文档,并最终返回完整的父文档作为检索结果。这种方法确保了上下文信息的完整性,避免了因信息缺失导致的理解偏差。
3. ParentDocumentRetriever的使用方法
使用ParentDocumentRetriever需要以下步骤:
- 加载文档: 使用合适的文档加载器(例如LangChain的TextLoader)加载需要索引的长文档。
- 文档分割: 使用RecursiveCharacterTextSplitter分别创建父文档和子文档分割器,控制父文档和子文档的大小。
- 向量数据库: 选择合适的向量数据库(例如Chroma),存储子文档的嵌入向量。
- 创建检索器: 创建ParentDocumentRetriever实例,指定向量数据库、文档存储、父文档和子文档分割器。
- 添加文档: 将加载的文档添加到ParentDocumentRetriever中。
- 进行查询: 使用`retriever.invoke()`方法进行查询,返回完整的父文档。
代码示例中,我们使用了OpenAIEmbeddings进行文本嵌入,并以Chroma作为向量数据库。 通过`retriever.invoke()`方法,我们可以直接获得包含完整上下文的父文档,而不是孤立的子文档片段。
4. 应用场景与优势
ParentDocumentRetriever特别适用于需要处理长文档的场景,例如:
- 法律文档分析: 返回完整的法律条款,避免因上下文缺失导致的理解错误。
- 企业知识库: 确保员工获取的知识完整且连贯,提高知识检索效率。
- 技术文档检索: 返回完整的API文档或代码示例,方便开发者理解和使用。
- 学术论文检索: 提供完整的论文段落,帮助读者更好地理解研究内容。
ParentDocumentRetriever的主要优势在于它兼顾了检索的精确性和上下文的完整性,显著提高了基于LLM的问答系统的质量。
5. 总结
ParentDocumentRetriever通过巧妙的分层检索机制,有效解决了传统向量搜索在处理长文档时容易出现的上下文缺失问题。它在各种需要处理长文档的应用场景中都具有显著的优势,是构建高质量LLM问答系统的重要工具。
联系作者
文章来源:AI取经路
作者微信:
作者简介:踏上取经路,比抵达灵山更重要! AI技术、 AI知识 、 AI应用 、 人工智能 、 大语言模型
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。