GAS – 卡内基梅隆联合上海 AI Lab 等推出的单图生成3D人体框架
GAS(Generative Avatar Synthesis from a Single Image)是一项由卡内基梅隆大学、上海人工智能实验室和斯坦福大学的研究团队提出的重要技术,旨在通过单张图像生成高质量、视角一致且动态连贯的虚拟形象。GAS的创新之处在于将回归型3D人体重建模型与扩散模型的优点相结合,使得从单一图像生成的虚拟形象在外观和结构上都显得异常真实。
GAS是什么
GAS(Generative Avatar Synthesis from a Single Image)是一种先进的框架,旨在从单张图像中合成高质量的虚拟形象。此技术由卡内基梅隆大学、上海人工智能实验室及斯坦福大学的研究人员共同开发。GAS的核心在于结合回归型3D人体重建模型和扩散模型的优势,通过3D人体重建生成中间的视角或姿态,并将其作为条件输入到视频扩散模型中,以实现高质量的视角一致性和时间连贯性。此外,该框架引入了“模式切换器”模块,以区分视角合成与姿态合成任务,进一步提升生成效果。
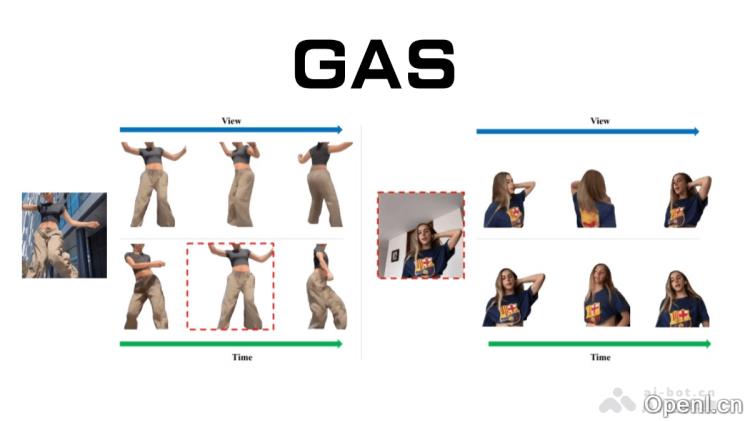
GAS的主要功能
- 一致性视角的多视角合成:GAS能够从单张图像生成高质量的多视角渲染,确保不同视角下的外观和结构保持一致。
- 动态姿态动画的时间连贯性:利用给定的姿态序列,GAS可生成流畅且真实的非刚性形变动画,确保动态姿态的自然连贯。
- 统一的框架与良好的泛化能力:该技术将视角合成与姿态合成任务相结合,通过共享模型参数和利用大规模真实数据(如网络视频)进行训练,显著提升模型对真实场景的适应能力。
- 密集外观提示:基于3D重建模型生成的密集信息作为条件输入,确保生成的结果在外观和结构上具有高保真度。
GAS的技术原理
- 3D人体重建与密集条件信号:GAS利用回归型3D人体重建模型(例如单视角通用人类NeRF)从输入图像生成中间视角或姿态,并通过将输入图像映射到规范空间生成密集的外观提示。这些信息为后续的扩散模型提供了丰富的细节和结构信息,从而确保生成结果的高质量和一致性。
- 视频扩散模型与统一框架:生成的中间视角或姿态作为视频扩散模型的条件输入,以此生成高质量的视角一致性和时间连贯性动画。GAS提出了一种统一框架,将视角合成和姿态合成任务合并,并共享模型参数,从而实现自然的任务泛化。
- 模式切换器:为了有效区分视角合成与姿态合成任务,GAS引入了模式切换器模块,确保在生成视角时专注于一致性,而生成姿态时则注重真实感变形。
- 真实世界数据的泛化能力:GAS通过结合大规模真实世界视频(如网络视频)进行训练,显著提升了对真实场景的适应能力。多样化的数据来源使得模型能够应对各种光照、服装和动作条件。
- 训练与推理:GAS的训练过程分为两个阶段:首先训练3D人体重建模型,然后冻结该模型并训练视频扩散模型。在推理阶段,依据任务的不同(视角合成或姿态合成)采用不同的分类器引导(CFG)策略。
GAS的项目地址
GAS的应用场景
- 游戏与虚拟现实(VR):GAS能够从单张图像生成高质量的虚拟角色,支持多视角和动态姿态的连贯合成,非常适合游戏和虚拟现实应用。
- 影视制作:在影视特效和动画制作领域,GAS能够快速生成逼真的虚拟角色,显著减少传统建模和动画制作所需的时间与成本。
- 体育与健身:通过从单张图像生成动态虚拟形象,GAS可用于创建个性化的动画,帮助员分析动作或用于健身应用。
- 时尚与服装设计:GAS能够生成不同姿态和视角的虚拟形象,帮助设计师快速预览服装效果,从而提升设计效率。
常见问题
- GAS生成的虚拟形象能否用于实际应用? 是的,GAS生成的虚拟形象在游戏、影视和其他创意领域都有广泛的应用潜力。
- 使用GAS需要什么样的输入? GAS仅需一张图像作为输入,便可生成高质量的虚拟形象。
- GAS的生成速度如何? 生成速度根据模型的复杂程度和硬件性能而有所不同,但整体上,GAS能够处理实时生成需求。
- GAS的技术是否开放? 是的,GAS的相关技术和论文已在其项目官网和arXiv上公开,欢迎研究人员和开发者探索。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。