通古大模型 – 华南理工大学推出的古籍大语言模型
通古大模型是一款由华南理工大学深度学习与视觉计算实验室(SCUT-DLVCLab)研发的人工智能语言模型,专注于古籍和文言文的处理。该模型基于百川2-7B-Base框架,通过增量预训练的方法,利用24.1亿古籍语料进行无监督学习,并结合400万古籍对话数据进行指令微调。通古大模型借助冗余度感知微调技术(RAT),显著提升了在古籍任务中的表现,旨在为用户提供更加便捷的古籍理解和翻译体验。同时,通过检索增强生成(CCU-RAG)技术,有效减少了知识密集型任务中的信息错误,提高了生成内容的准确性和可靠性。
通古大模型是什么
通古大模型是华南理工大学深度学习与视觉计算实验室(SCUT-DLVCLab)推出的一款专注于古籍文言文处理的人工智能语言模型。该模型以百川2-7B-Base为基础,通过增量预训练,利用24.1亿古籍语料进行无监督学习,并结合400万古籍对话数据进行指令微调。采用冗余度感知微调(RAT)技术,有效提升了古籍处理任务的性能,为用户理解和翻译古籍文献提供了便利。通过检索增强生成(CCU-RAG)技术,有效减少知识密集型任务中的幻觉现象,提高生成内容的准确性与可靠性。
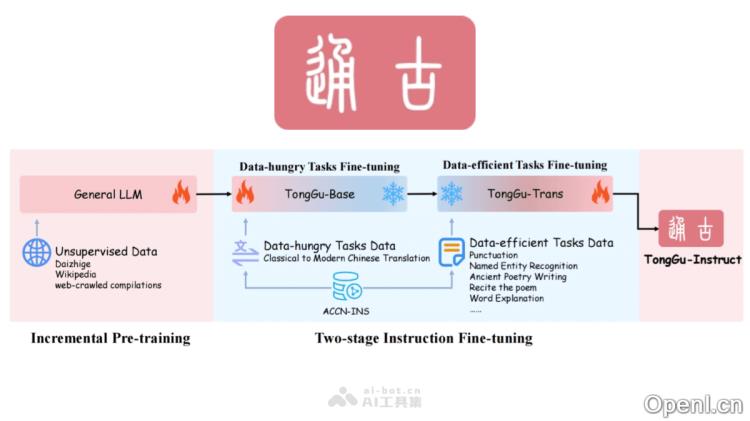
主要功能
- 古文句读:该模型能够自动为古文添加标点,解决古籍文献中的断句困扰,帮助用户更好地理解古文。
- 文白翻译:通古大模型支持文言文与现代白话文之间的双向翻译,能够将复杂的古文转化为现代语言,同时也能将现代文转为文言文,便于用户进行古籍阅读及研究。
- 诗词创作:模型可以根据用户提供的主题或关键词,生成符合古诗词的格律与风格的作品,满足用户的创作需求。
- 古籍赏析:通古大模型能够对古籍中的经典篇章进行深度解读,分析其文学价值、历史背景及文化内涵,帮助用户深入学习古籍。
- 古籍检索与问答:借助检索增强技术,模型能够快速检索古籍内容,并根据用户提问给出准确的答案,帮助用户高效获取信息。
- 辅助古籍整理:该模型能够识别古籍中的文字错误和缺漏,提供修复建议,支持古籍的整理和数字化工作。
产品官网
- Github仓库:https://github.com/SCUT-DLVCLab/TongGu-LLM
- HuggingFace模型库:https://huggingface.co/SCUT-DLVCLab/TongGu-7B-Instruct
应用场景
- 古籍处理与数字化:通古大模型能够高效处理古籍文献,支持文白翻译、句读标点和古籍检索等功能,助力古籍整理工作,提升数字化效率。
- 教育支持:教师可以利用该模型生成教案、制作教学PPT,并设计课堂互动环节;而学生则可以通过模型获取文言文翻译、成语解释和诗词创作等功能,增强对古文的理解。
- 文化传承与普及:通古大模型降低了古籍阅读的难度,使更多人能够接触和理解中华传统文化。
- 学术研究:为古籍研究提供强大的技术支持,帮助学者快速检索和分析古籍内容。
常见问题
- 通古大模型适合哪些人群使用? 该模型适合古籍研究者、学生、教师以及对中华传统文化感兴趣的广大用户。
- 如何获取通古大模型? 用户可以通过访问其GitHub和HuggingFace页面获取相关资源和使用说明。
- 通古大模型是否支持多种语言? 目前,模型主要支持文言文与现代白话文之间的双向翻译。
- 使用通古大模型需要什么技术基础? 使用者无需专业的技术背景,但了解基础的古文知识将有助于更好地利用模型的功能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。