EPLB – DeepSeek 开源的专家并行负载均衡器
EPLB(Expert Parallelism Load Balancer)是一款由DeepSeek开发的专家并行负载均衡器,旨在解决大规模模型训练中不同专家模型(Expert)之间负载不均的问题。EPLB采用冗余专家策略,通过复制高负载专家并合理分配至不同的GPU,从而实现负载均衡。此外,EPLB结合了group-limited expert routing技术,将同一组的专家放置在同一节点内,以减少跨节点的通信开销。
EPLB是什么
EPLB(Expert Parallelism Load Balancer)是DeepSeek推出的一款专家并行负载均衡器,专门用于解决在大规模模型训练中,各专家模型负载不均的问题。它通过冗余专家策略,复制负载较高的专家并合理分配到不同的GPU上,实现负载均衡。EPLB结合了group-limited expert routing技术,将同组专家安排在同一节点内,从而降低跨节点通信的开销。EPLB提供了两种负载均衡策略:分层负载均衡(Hierarchical Load Balancing)和全局负载均衡(Global Load Balancing),适用于不同的使用场景。通过优化专家模型的复制与分配,EPLB显著提升了GPU资源的利用率和训练效率。

EPLB的主要功能
- 负载均衡:根据专家的负载估计,动态调整复制和分配策略,确保不同GPU之间的负载差异最小化。
- 专家复制:通过冗余专家策略,复制高负载的专家,从而缓解负载不均的问题。
- 资源优化:最大限度地利用GPU资源,减少因负载不均而产生的性能瓶颈,提高训练效率。
- 通信优化:通过合理的专家放置策略,降低节点间的通信开销和延迟。
- 灵活的策略支持:提供层次化负载均衡和全局负载均衡两种策略,以适应不同的场景和阶段。
- 多层MoE模型支持:能够处理复杂的多层混合专家模型,支持灵活的专家分配和映射。
EPLB的技术原理
- 冗余专家策略:在专家并行中,不同专家的负载因输入数据和模型结构的差异而异。引入冗余专家(复制高负载专家)以平衡负载,支持高负载专家的多次复制和分散到多个GPU上,避免单一GPU的过载。
- 层次化负载均衡:将专家组均匀分配到不同的节点,确保每个节点的负载大致相等。在每个节点内,进一步复制专家并将其分配到该节点的GPU上,确保节点内部的负载均衡,尽量将同组专家放在同一节点内,以减少跨节点的通信开销。
- 全局负载均衡:在节点数无法整除专家组数或需要更大规模并行的情况下,采用全局策略,忽略专家组的限制,将专家全局复制并分配到所有可用的GPU上。基于动态调整专家的复制数量和放置位置,确保全局负载均衡。
- 负载估计与动态调整:EPLB使用专家负载的估计值来指导负载均衡策略。负载估计基于历史统计数据(如移动平均值)。根据负载估计值,动态调整专家的复制和分配策略,以适应不同的训练阶段和数据分布。
- 专家映射与资源分配:基于rebalance_experts函数生成的专家复制和放置计划,将专家映射到具体的GPU上。输出的映射关系包括物理到逻辑(phy2log)和逻辑到物理(log2phy)的映射,以及每个专家的复制数量(logcnt)。
EPLB的项目地址
- GitHub仓库:https://github.com/deepseek-ai/eplb
EPLB的核心模式
- 层次化负载均衡模式(Hierarchical Load Balancing):在节点数能整除专家组数时,基于分层负载均衡策略,优化节点内和节点间的负载分配。
- 全局负载均衡模式(Global Load Balancing):在节点数无法整除专家组数或需要更大规模并行时,基于全局复制和分配专家,实现整体负载均衡。
EPLB的代码演示示例
- 代码示例展示了一个两层MoE模型的实现,每层包含12个专家。每层引入4个冗余专家,总共16个副本分布在2个节点上,每个节点配备4个GPU。
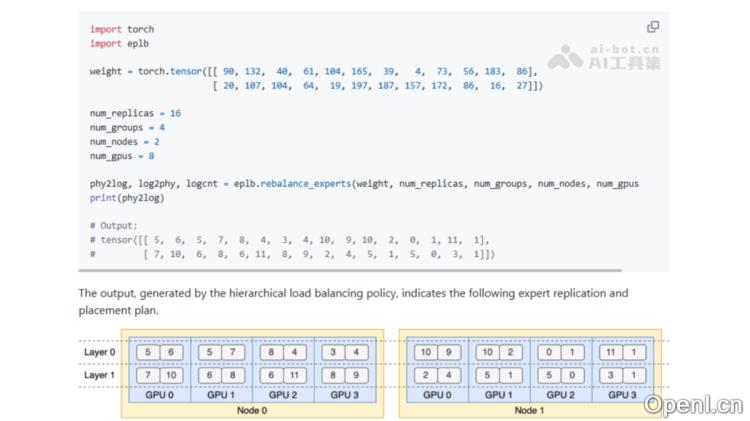
EPLB的应用场景
- 大规模分布式训练:适用于多节点、多GPU环境,灵活切换层次化或全局负载均衡模式,优化资源利用,减少通信开销。
- 预填充阶段:在模型训练初期,基于层次负载均衡减少跨节点通信,提高小规模并行的效率。
- 解码阶段:在训练后期需要大规模并行时,采用全局负载均衡动态调整负载,以应对复杂任务。
- 异构硬件环境:当节点数与专家组数不匹配时,全局负载均衡模式可以灵活适应异构配置,实现高效的负载均衡。
- 动态负载变化:针对训练过程中负载的动态变化,结合层次化或全局负载均衡策略实时调整,以确保训练过程的高效与稳定。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。