AIMv2 – 苹果开源的多模态自回归预训练视觉模型
AIMv2是什么
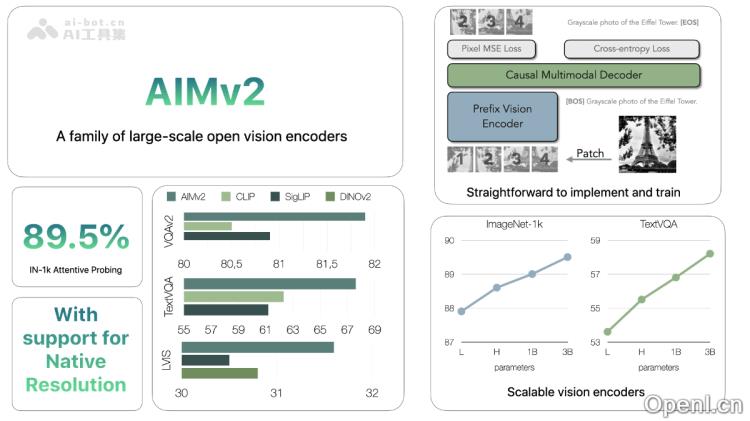
AIMv2是苹果公司推出的开源多模态自回归预训练视觉模型,通过深度融合图像和文本信息,提高视觉模型的性能。它采用了一种创新的预训练框架,将图像切分为非重叠的图像块,并将文本拆分为子词令牌,随后将这两种信息合并为一个统一的序列进行自回归预训练。这一方法简化了训练过程,并显著增强了模型对多模态数据的理解能力。AIMv2提供多种参数规模的版本(如300M、600M、1.2B和2.7B),能够适应从手机到PC的不同设备。在性能方面,AIMv2在多模态任务和传统视觉任务中均表现优异。
AIMv2的主要功能
- 视觉问答(VQA):AIMv2能够提取图像特征,并将其与问题文本结合,传递给大型语言模型(LLM),从而生成准确且符合上下文的回答。
- 指代表达理解:在RefCOCO和RefCOCO+等基准测试中,AIMv2能够精确地将自然语言描述与图像区域相对应。
- 图像字幕生成:结合LLM,AIMv2能够产生高质量的图像描述。
- 多媒体检索:AIMv2强大的多模态表示能力使其能够高效处理多媒体检索任务,支持图像与文本的联合检索。
- 与大型语言模型(LLM)集成:AIMv2的架构与LLM驱动的多模态应用高度契合,能够无缝融入各种多模态系统中。
- 零样本适应性:AIMv2支持零样本识别适应性,能够在没有额外训练的情况下适应新的视觉任务。
AIMv2的技术原理
- 多模态自回归预训练框架:AIMv2将图像分割为不重叠的小块(Patch),将文本分解为子词标记,随后将两者拼接为一个多模态序列。在预训练阶段,模型通过自回归方式预测序列中的下一个元素,无论是图像块还是文本标记。这种设计使模型能够同时学习视觉和语言模态之间的关系。
- 视觉编码器与多模态解码器:AIMv2的架构由视觉编码器和多模态解码器组成。视觉编码器基于视觉Transformer(ViT)架构,负责处理图像Patch,而多模态解码器则利用因果自注意力机制,根据前文内容预测下一个元素。
- 损失函数设计:AIMv2为图像和文本领域定义了各自的损失函数。文本损失采用标准的交叉熵损失,而图像损失则使用像素级回归损失,用于比较预测的图像块与真实图像块。整体目标是最小化文本损失和图像损失的加权和,以平衡模型在两个模态上的表现。
- 训练数据与扩展性:AIMv2使用了大量的图像和文本配对数据集进行预训练,包括公开的DFN-2B和COYO数据集。训练过程简便高效,无需过大的批量大小或特殊的跨批次通信方法。随着数据量和模型规模的增加,AIMv2的性能也不断提升,展现出良好的可扩展性。
- 预训练后的优化策略:AIMv2探索了多种训练后策略,如高分辨率适配和原始分辨率微调。这些策略使模型能够更好地处理不同分辨率和宽高比的图像,进一步提升其在下游任务中的表现。
AIMv2的项目地址
- Github仓库:https://github.com/apple/ml-aim
- arXiv技术论文:https://arxiv.org/pdf/2411.14402
AIMv2的应用场景
- 图像识别:AIMv2可作为特征提取器,用于多项图像识别基准测试。
- 目标检测与实例分割:AIMv2可作为主干网络集成到目标检测模型(如Mask R-CNN)中,应用于目标检测与实例分割任务。
- 开放词汇对象检测:AIMv2在开放词汇对象检测任务中表现优异,能够识别和定位未见过的类别,展现出强大的泛化能力。
常见问题
- AIMv2支持哪些设备? AIMv2提供多种参数规模的版本,适用于从手机到PC等各种设备。
- AIMv2的性能如何? AIMv2在多模态任务和传统视觉任务中均表现出色,展现出强大的处理能力。
- 如何获取AIMv2的资源? 用户可以通过其Github仓库和arXiv论文获取AIMv2的相关资源和文档。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。