阿里巴巴开源ViDoRAG:视觉文档理解的全新突破
人工智能领域持续发展,对复杂信息处理的需求日益增长。近日,阿里巴巴通义实验室开源了一款名为ViDoRAG的创新型视觉文档理解系统,在检索增强生成(RAG)技术上取得了显著突破,为该领域带来了新的可能性。
多智能体框架:高效处理多模态信息
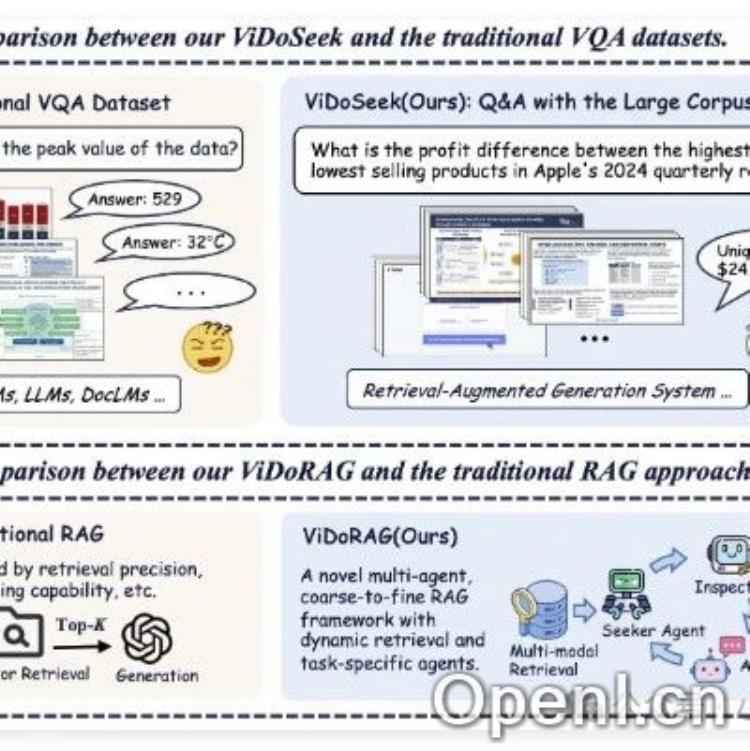
不同于传统的单一模型,ViDoRAG采用创新的多智能体框架。它整合了动态迭代推理代理和基于高斯混合模型(GMM)的混合检索技术。这种设计允许ViDoRAG高效地处理包含图像和文本的视觉文档,从复杂的视觉信息中准确提取和推理关键信息。通过多模态数据融合,ViDoRAG克服了传统RAG系统仅依赖文本检索的局限性,显著提升了理解精度和效率。
性能提升:准确率显著提高
在GPT-4o模型上的测试结果显示,ViDoRAG的准确率达到了79.4%,比传统RAG系统提升了10%以上。这一显著的性能提升源于其对视觉和文本信息的深度融合。对于需要高精度文档理解的应用场景,例如法律文件分析、医疗报告解读和企业数据处理,ViDoRAG的准确性提升具有极高的价值。
开源的意义:推动技术发展与共享
阿里巴巴通义实验室将ViDoRAG开源,这一举措在Twitter上引发了热烈讨论。开源不仅展示了阿里巴巴在人工智能领域的领先技术实力,更重要的是,它为全球开发者和研究人员提供了一个宝贵的资源。通过公开论文和代码,ViDoRAG有望加速视觉文档RAG技术的研究与应用,促进多模态人工智能系统的进一步发展,推动整个领域的进步。
未来展望:引领视觉文档理解新方向
随着对视觉文档处理需求的不断增长,ViDoRAG的出现只是一个开端。其创新性的多智能体框架和显著的性能提升,为视觉文档理解领域指明了新的方向。未来,我们有理由期待更多类似的创新系统涌现,共同推动人工智能技术在更广泛领域的应用,为社会创造更大的价值。
联系作者
文章来源:小夏聊AIGC
作者微信:
作者简介:专注于人工智能生成内容的前沿信息与技术分享。我们提供AI生成艺术、文本、音乐、视频等领域的最新动态与应用案例。每日新闻速递、技术解读、行业分析、专家观点和创意展示。期待与您一起探索AI的无限潜力。欢迎关注并分享您的AI作品或宝贵意见。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。