SepLLM – 基于分隔符压缩加速大语言模型的高效框架
SepLLM是什么
SepLLM是由香港大学、华为诺亚方舟实验室等机构共同研发的一种高效框架,旨在加速大语言模型(LLM)的推理过程。通过有效压缩段落信息并去除冗余标记,SepLLM显著提升了模型的推理速度和计算效率。该框架的核心创新在于利用分隔符(例如标点符号)在注意力机制中的作用,将段落信息浓缩于这些标记之中,从而减轻计算负担。SepLLM在处理长序列(如400万个标记)时表现出色,成功保持了低困惑度和高效率。此外,它支持多节点分布式训练,并集成了多种加速操作(如fused rope和fused layer norm)。
SepLLM的主要功能
- 长文本处理能力:SepLLM具备高效处理超过400万个标记的能力,特别适合于文档摘要和长对话等需要保持上下文连贯性的任务。
- 推理与内存效率提升:在GSM8K-CoT基准测试中,SepLLM将KV缓存的使用量减少了50%以上,计算成本降低28%,训练时间缩短26%,并显著提高了推理速度。
- 多场景部署灵活性:SepLLM支持从头训练、微调以及流式应用等多种部署方式,能够与预训练模型无缝结合。
- 支持多节点分布式训练:该框架的代码库支持高效的多节点分布式训练,并集成了多种加速训练的操作(如fused rope和fused layer norm等)。
SepLLM的技术原理
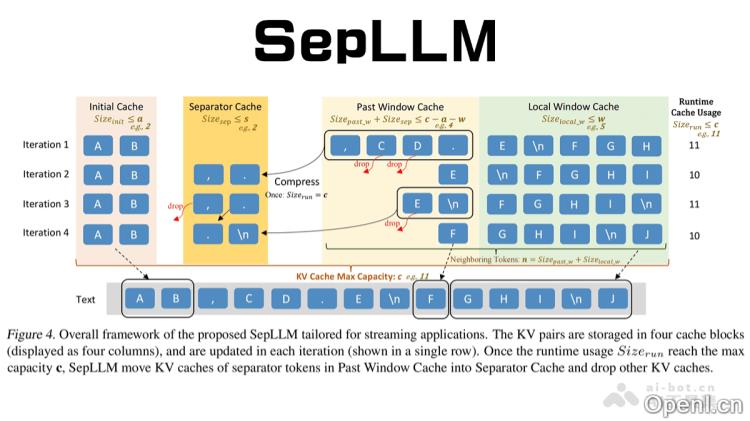
- 稀疏注意力机制:SepLLM专注于三类标记。在自注意力层中,利用mask矩阵限制注意力计算的范围,仅计算这三类标记之间的注意力,从而实现稀疏化。
- 初始标记(Initial Tokens):序列开头的若干标记,作为注意力的锚点。
- 邻近标记(Neighboring Tokens):当前标记附近的标记,以维持局部语义的连贯性。
- 分隔符标记(Separator Tokens):诸如逗号、句号等,用于压缩存储段落信息。
- 动态KV缓存管理:SepLLM设计了专门的缓存块,包括初始缓存、分隔符缓存、历史窗口缓存和局部窗口缓存。通过周期性的压缩和更新策略,SepLLM能有效处理长序列,同时减少KV缓存的使用。
SepLLM的项目地址
- 项目官网:https://sepllm.github.io/
- Github仓库:https://github.com/HKUDS/SepLLM
- arXiv技术论文:https://arxiv.org/pdf/2412.12094
SepLLM的应用场景
- 流式应用:适用于多轮对话和实时文本生成等流式场景,支持无限长度的输入,同时保持高效的语言建模能力。
- 推理与内存优化:通过减少KV缓存和计算成本,适合资源有限的环境(如边缘计算和移动设备),从而降低部署成本。
- 工业应用:在大规模商业应用中,降低部署成本,提升服务效率,支持高并发请求。
- 研究与创新:为优化注意力机制提供新思路,支持多语言、特定领域优化以及硬件适配等研究方向。
常见问题
- SepLLM适合哪些应用场景? SepLLM特别适合需要处理长文本和高效推理的应用场景,如文档摘要、对话系统等。
- 如何获取SepLLM? 用户可以访问SepLLM的官方网站或Github仓库下载相关资源和文档。
- SepLLM的性能如何? 在多项基准测试中,SepLLM展现了显著的性能提升,包括降低计算成本和提高推理速度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。