OmniAlign-V – 上海交大联合上海 AI Lab 等推出的高质量数据集
OmniAlign-V 是一个由上海交通大学、上海AI Lab、学、复旦大学和浙江大合开发的高质量多模态数据集,旨在增强多模态大语言模型(MLLMs)与人类偏好的对齐能力。该数据集包含约20万个多模态训练样本,涵盖自然图像和信息图表,并结合开放式、知识丰富的问题与答案。
OmniAlign-V是什么
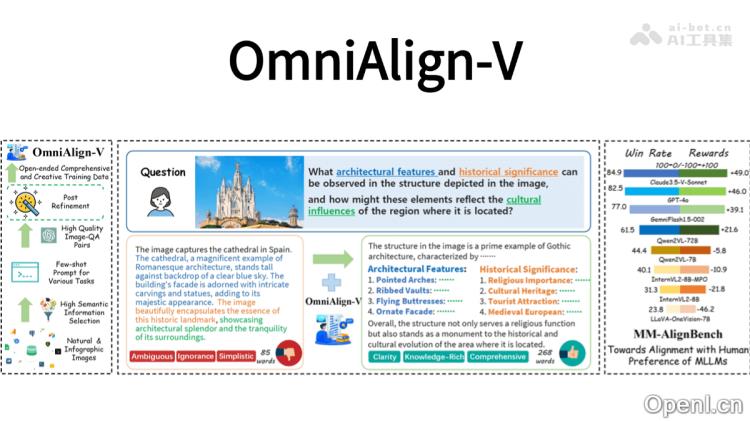
OmniAlign-V是专为提高多模态大语言模型(MLLMs)与人类偏好之间的对齐能力而设计的高质量数据集。此数据集由上海交通大学、上海AI Lab、学、复旦大学和浙江大合推出,包含约20万个多模态训练样本,涵盖自然图像和信息图表,结合复杂问题和多样化的回答格式,以帮助模型更好地理解人类的需求和偏好。OmniAlign-V注重任务的多样性,设计了知识问答、推理和创造性任务,以提升模型的对齐能力。同时,引入了图像筛选策略,以确保用于数据生成的图像具有丰富且复杂的语义。
OmniAlign-V的主要功能
- 提供高质量的多模态训练数据:包含约20万个多模态样本,涵盖自然图像和信息图表(如海报、图表等),结合复杂的问题与多样化的回答格式,帮助模型更精准地理解人类的需求。
- 增强开放式问答能力:通过设计重点关注开放式问题和跨学科知识,提升模型生成符合人类偏好的回答的能力。
- 提升推理和创造性能力:训练模型进行更复杂的思考与创作,以增强其在多模态交互中的表现。
- 优化多模态指令调优:利用高质量的指令调优数据,确保模型能够更好地遵循人类的指令,并保留基础能力(如目标识别、OCR等)。
- 支持多模态模型的持续优化:OmniAlign-V用于监督微调(SFT),结合直接偏好优化(DPO)进一步提升模型的对齐能力。
OmniAlign-V的技术原理
- 图像筛选与分类:依据图像复杂度(IC)评分和对象类别(OC)进行筛选,确保选择出语义丰富且复杂的图像。图像被分类为自然图像和信息图表,针对不同类型的图像设计相应的任务。
- 任务设计与数据生成:自然图像的任务包括知识问答、推理和创造性任务,以提升模型对真实场景的理解及生成能力。信息图表的任务则专注于图表和海报等,要求模型具备对复杂信息的理解与解释能力。通过使用GPT-4o等先进模型生成高质量的问答对,并进行后处理以优化数据质量。
- 后处理优化:对生成的问答对进行后处理,包括指令增强、推理增强和信息图表答案的精细化处理,以确保数据的多样性和高质量。
- 多模态训练与优化:通过监督微调(SFT)和直接偏好优化(DPO)提升模型的对齐能力。数据集设计强调多样性和复杂性,使模型在多模态交互中更好地理解人类偏好。
- 基准测试与评估:引入MM-AlignBench基准测试,以评估MLLMs在人类偏好对齐方面的表现,确保模型在真实场景中的有效性。
OmniAlign-V的项目地址
- 项目官网:https://phoenixz810.github.io/OmniAlign-V
- GitHub仓库:https://github.com/PhoenixZ810/OmniAlign-V
- HuggingFace模型库:https://huggingface.co/collections/PhoenixZ/omnialign-v
- arXiv技术论文:https://arxiv.org/pdf/2502.18411
OmniAlign-V的应用场景
- 多模态对话系统:提升智能助手与用户的互动质量,提供更符合人类偏好的回答。
- 图像辅助问答:结合图像信息,提供全面而准确的问答服务,适合教育、旅游等行业。
- 创意内容生成:帮助用户快速生成高质量的创意文本,例如广告文案、故事创作等。
- 教育与学习辅助:为学生提供更丰富的学习材料,支持对复杂图表和插图的理解。
- 信息图表解读:协助用户解读复杂图表,提供背景知识和推理结果,提升数据理解能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。