MHA2MLA – 复旦、上海AI Lab等推出优化LLM推理效率的方法
MHA2MLA是一种由复旦大学、华东师范大学及上海AI Lab等多家机构共同开发的数据高效微调方法。该方法采用了DeepSeek的多头潜在注意力机制(MLA),旨在提升任何基于Transformer的大型语言模型(LLM)的推理效率,并显著降低推理成本。MHA2MLA通过两个核心策略实现其目标:首先是部分旋转位置编码(partial-RoPE),去除了对注意力分数贡献较小的查询和键的旋转位置编码(RoPE)维度;其次是低秩近似,通过联合奇异值分解(SVD)对键和值进行压缩,从而减少KV缓存的内存占用。该方法仅需使用原始数据的0.3%至0.6%进行微调,即可在极大降低KV缓存(如高达92.19%)的同时,将性能损失控制在微小范围内(例如LongBench性能仅下降0.5%)。
MHA2MLA是什么
MHA2MLA是由复旦大学、华东师范大学和上海AI Lab等机构联合研发的一种高效微调方法,旨在优化基于Transformer的LLM的推理过程。通过引入DeepSeek的多头潜在注意力机制(MLA),MHA2MLA能够降低推理成本并提升推理效率。该方法依赖于两个重要策略:部分旋转位置编码(partial-RoPE)和低秩近似(Low-Rank Approximation),实现了在数据量极小的情况下,依然能够保持模型的高性能。
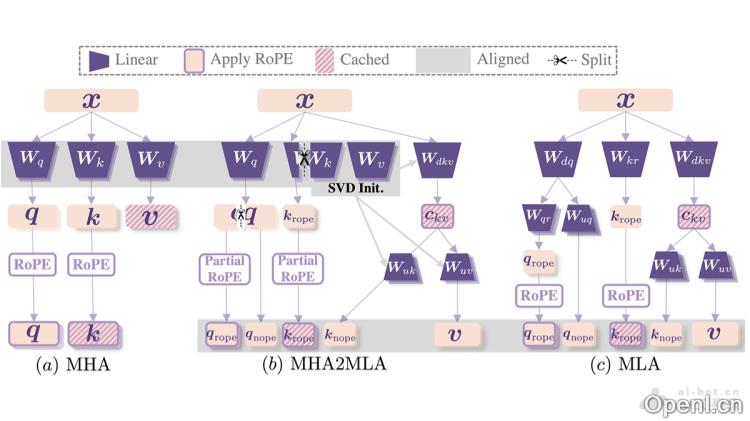
MHA2MLA的主要功能
- 显著降低KV缓存:基于低秩压缩技术,最大限度地减少KV缓存的大小(最高可达96.87%),从而降低推理过程中的内存占用。
- 保持模型性能:在极少量数据(0.3%至0.6%原始训练数据)下进行微调,确保性能损失极小(如LongBench性能仅下降0.5%)。
- 兼容现有技术:可与量化技术(如4-bit量化)结合使用,进一步提升推理效率。
- 数据高效性:仅需少量数据即可完成从MHA到MLA的架构转变,适合在资源受限的环境中快速实施。
MHA2MLA的技术原理
- 部分旋转位置编码(Partial-RoPE):在多头自注意力机制中,旋转位置编码(RoPE)通过旋转操作将位置信息融入查询向量(Q)和键向量(K),帮助模型捕捉序列中的位置信息。MHA2MLA根据每个维度对注意力分数的贡献,移除贡献较小的RoPE维度,减少计算量和内存占用,这一过程称为部分RoPE,从而为低秩压缩腾出空间。
- 低秩近似(Low-Rank Approximation):MLA利用低秩联合压缩键值(KV)来减少内存占用。MHA2MLA借鉴这一思想,对MHA中的键和值参数矩阵进行奇异值分解(SVD),将其分解为低秩矩阵的乘积,以更少的参数近似原始矩阵。为了更好地保留键和值之间的交互信息,MHA2MLA采用联合SVD(SVDjoint)策略,对键和值矩阵进行联合分解,而非各自处理。
MHA2MLA的项目地址
- GitHub仓库:https://github.com/JT-Ushio/MHA2MLA
- arXiv技术论文:https://arxiv.org/pdf/2502.14837
MHA2MLA的应用场景
- 边缘设备部署:通过降低模型的内存占用,使其适应资源受限的智能终端和物联网设备。
- 大规模模型推理:减少KV缓存,提高推理效率,降低硬件需求和能耗。
- 结合量化技术:与量化技术结合,进一步优化推理性能,适用于实时对话和在线翻译等应用。
- 长文本处理:缓解长文本任务中的内存瓶颈,高效处理长文档摘要和长篇生成。
- 快速模型迁移:仅需少量数据微调,迅速将MHA模型转变为MLA架构,降低迁移成本。
常见问题
- MHA2MLA适合哪些场景? MHA2MLA特别适合资源受限的环境,如边缘设备和物联网应用,同时也适用于大规模模型推理和长文本处理。
- 微调时需要多少数据? 只需使用原始数据的0.3%到0.6%进行微调,即可实现有效的性能保持。
- 与其他技术兼容吗? 是的,MHA2MLA可以与量化技术等其他优化方法结合使用,进一步提升推理效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。