CogVideoX是什么
CogVideoX是智谱AI最新发布的一款开源AI视频生成模型,它与智谱AI的商业产品“清影”有着共同的技术基础。CogVideoX能够接受英文提示词,生成时长为6秒、帧率为每秒8帧、分辨率为720*480的视频。推理过程中需要的显存范围在7.8GB至26GB之间,目前尚不支持量化推理和多卡推理。该项目还包含了3D Causal VAE组件用于视频重建,配备丰富的示例和工具,包括CLI/WEB演示、在线体验、API接口示例以及微调指南。
CogVideoX的主要功能
- 文本生成视频:用户可以通过输入文本提示,生成相应的视频内容。
- 显存需求低:在INT8精度下,推理显存仅需7.8GB,使用1080 Ti显卡也能完成推理。
- 视频参数定制:支持用户自定义视频的长度、帧率和分辨率,当前版本支持生成6秒长、8帧/秒、720*480分辨率的视频。
- 3D Causal VAE技术:通过3D Causal VAE技术,实现视频内容的高效重建。
- 推理与微调:模型不仅支持基本的推理生成视频,还提供了微调功能,以满足不同需求。
CogVideoX的技术原理
- 文本到视频生成:CogVideoX利用深度学习模型,特别是基于Transformer的架构,来解析输入的文本提示并生成视频内容。
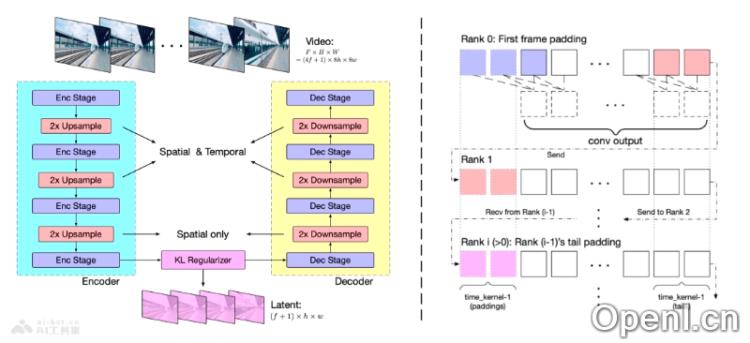
- 3D Causal VAE:该模型采用了3D Causal Variational Autoencoder(变分自编码器),这是一种用于视频重建和压缩的技术,能够几乎无损地重建视频,降低存储和计算需求。
- 专家Transformer:CogVideoX运用了专家Transformer模型,这是一种特殊的Transformer架构,通过多个专家协同处理不同的任务,比如空间与时间信息的处理,以及控制信息流动等。
- 编码器-解码器架构:在3D VAE中,编码器将视频转换为简化的代码,而解码器根据这些代码重建出视频,潜在空间正则化器确保编码和解码之间的信息传递更加准确。
- 混合时长训练:CogVideoX采用混合时长训练法,使模型能够学习生成不同长度的视频,提高其泛化能力。
- 多阶段训练:训练过程分为多个阶段,包括低分辨率预训练、高分辨率预训练及高质量视频微调,逐步提升模型的生成质量与细节。
- 自动与人工评估:CogVideoX结合自动评估和人工评估的方式,以确保生成视频的质量符合预期。
CogVideoX的项目地址
- 智谱清影体验:https://openi.cn/chatglm-video/
- CogVideoX-2B模型地址:
- HuggingFace模型库:https://huggingface.co/THUDM/CogVideoX-2b
- 魔搭社区模型库:https://modelscope.cn/models/ZhipuAI/CogVideoX-2b
- CogVideoX-5B模型地址:
- GitHub仓库:https://github.com/THUDM/CogVideo
- arXiv技术论文:https://arxiv.org/pdf/2408.06072
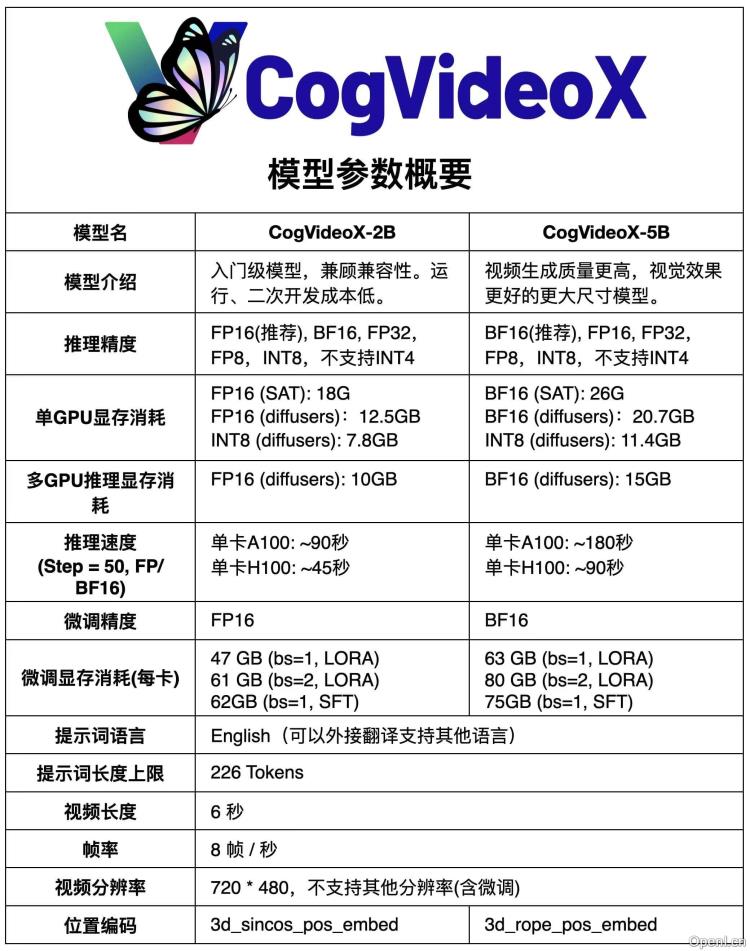
CogVideoX-2B与CogVideoX-5B参数对比
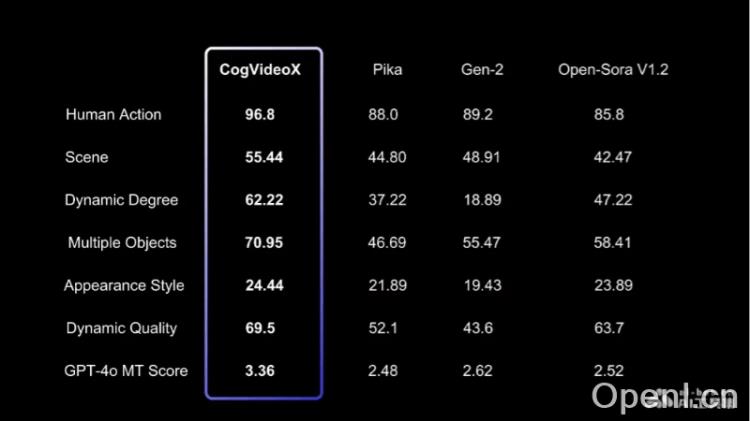
CogVideoX的性能评估
为评估文本到视频生成的质量,我们采用了VBench中的多项指标,包括人类动作、场景及动态程度等。此外,还使用了两个额外的视频评估工具:Devil中的动态质量和Chrono-Magic中的GPT4o-MT评分,这些工具专注于视频的动态特性,如下表所示。
CogVideoX的应用场景
- 创意视频制作:为视频创作者和艺术家提供工具,快速将创意文本描述转化为生动的视频内容。
- 教育与培训材料:自动生成教育视频,有助于阐释复杂概念或展示教学场景。
- 广告与品牌宣传:企业可以利用CogVideoX模型基于广告文案生成视频广告,提升营销效果。
- 游戏与娱乐产业:辅助游戏开发者快速生成游戏内动画或剧,增强游戏体验。
- 电影与视频编辑:帮助视频编辑人员通过文本描述生成特定场景或特效视频。
- 虚拟现实(VR)与增强现实(AR):为VR和AR应用生成沉浸式视频内容,提升用户互动体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 粤公网安备 44011502001135号
粤公网安备 44011502001135号