DreamVideo-2是一款突破性的零样本视频定制框架,由复旦大学与阿里巴巴集团等机构联合开发。该框架能够根据单一图像和一系列界定框,生成带有特定主题和精准轨迹的视频,且在测试过程中无需进行微调。DreamVideo-2采用参考注意力机制学习主题的外观,并通过从界定框导出的二值掩码来控制轨迹,实现高精度的管理。
DreamVideo-2是什么
DreamVideo-2是一种创新的零样本视频定制框架,由复旦大学与阿里巴巴集团等机构共同推出。它能够根据用户提供的单一图像和界定框序列生成特定主题和轨迹的视频,无需在测试时进行任何微调。该框架利用参考注意力机制来学习主题的外观,并基于从界定框生成的二值掩码来控制轨迹,从而实现精准的管理。DreamVideo-2引入混合掩码参考注意力和重加权扩散损失,这增强了主题表征,并平衡了主题学习与控制之间的关系。研究团队利用WebVid-10M数据集和内部数据来支持零样本视频定制任务,结果显示DreamVideo-2在主题定制和控制方面超越了现有的先进方法,展现了其在视频定制领域的巨大潜力和实用性。
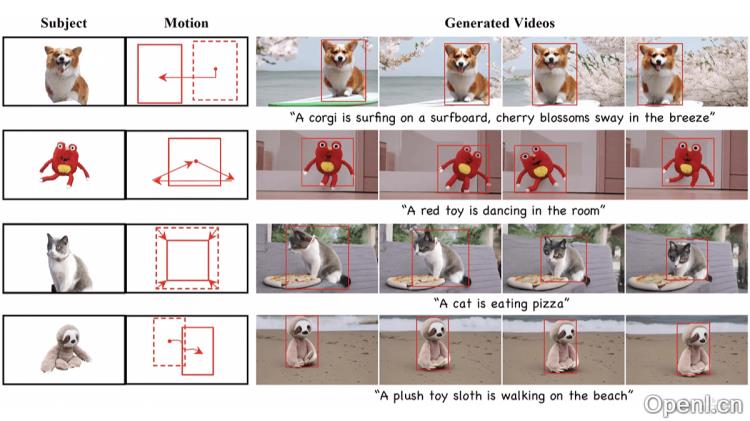
DreamVideo-2的主要功能
- 零样本定制:无需在测试时进行微调,能够直接根据用户提供的单一图像和界定框序列生成具有特定主题和精确轨迹的视频。
- 主题学习:基于参考注意力机制,利用模型的固有能力学习和生成特定主题的外观。
- 精确控制:通过从界定框导出的二值掩码控制视频中主题的轨迹,实现精确的控制。
- 混合掩码参考注意力:基于混合潜在掩码建模方案,增强目标位置的主题表征,从而提升主题的准确性。
- 重加权扩散损失:通过区分界定框内外区域的贡献,确保主题学习和控制之间的平衡。
DreamVideo-2的技术原理
- 参考注意力机制:
- 基于视频扩散模型的多尺度特征提取能力,将用户提供的单一主题图像作为单帧视频输入模型,获取主题注意力特征。
- 通过残差交叉注意力将主题特征融入视频特征中,从而增强模型对特定主题的学习能力。
- 掩码引导的模块:
- 将用户定义的界定框序列转换为二值掩码序列,以指示视频中主题的轨迹。
- 设计包含时空编码器和空间ControlNet的掩码引导模块,从掩码序列中提取信息,实现精确控制。
- 混合掩码参考注意力:在参考注意力中引入混合潜在掩码建模,通过调整掩码中背景的权重,增强目标位置的主题表征。
- 重加权扩散损失:设计新的损失函数,通过调整界定框内外区域的损失贡献权重,确保主题学习与控制之间的平衡。
- 训练与推理:
- 在训练阶段,冻结原始3D UNet参数,联合训练新添加的组件,如混合掩码参考注意力和掩码引导的模块。
- 在推理阶段,用户提供主题图像和界定框序列,能够生成定制视频,无需额外的微调或注意力图修改。
- 数据集构建:构建新的单主题视频数据集,包含视频掩码和边界框,通过Grounding DINO、SAM和DEVA模型生成注释,支持零样本视频定制任务。
DreamVideo-2的项目地址
- 项目官网:dreamvideo2.github.io
- arXiv技术论文:https://arxiv.org/pdf/2410.13830
DreamVideo-2的应用场景
- 娱乐与社交媒体:用户可以根据个人喜好,快速生成包含特定人物或物体的视频内容,适用于社交媒体分享或个人娱乐。
- 电影与视频制作:电影制作人可以利用DreamVideo-2预览特效或场景,或生成特定的动作序列,从而降低实际拍摄的成本和时间。
- 广告与营销:企业可以基于定制的视频内容,创建更具吸引力的广告,以特定产品或品牌为主题,提高广告的个性化和互动性。
- 教育与培训:教育机构可以使用DreamVideo-2生成教学视频,模拟特定实验过程或历史,增强学习体验。
- 新闻与报道:新闻机构能够快速生成新闻故事的视觉内容,尤其适合于那些难以现场拍摄的。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 粤公网安备 44011502001135号
粤公网安备 44011502001135号