Infinity-MM是智源研究院推出的一个规模庞大的多模态指令数据集,拥有4300万条样本,总数据量达到10TB。经过严格的质量筛选与去重,Infinity-MM保证了数据的高质量与多样性,这为提升开源视觉-语言模型(VLMs)的性能提供了坚实基础。同时,智源还开发了基于开源VLMs的合成数据生成技术,进一步扩展了数据集的规模和多样性。这一数据集支持智源成功训练了一个20亿参数的多模态模型Aquila-VL-2B,并在多个基准测试中取得了卓越的成绩。
Infinity-MM是什么
Infinity-MM是智源研究院推出的一个千万级多模态指令数据集,包含4300万条样本,数据量高达10TB。数据集经过严格的质量过滤和去重,确保了数据的高质量和多样性,旨在提升开源视觉-语言模型(VLMs)的性能。智源还推出了基于开源VLMs的合成数据生成方法,进一步扩展了数据集的规模和多样性。基于Infinity-MM,智源成功训练了20亿参数的多模态模型Aquila-VL-2B,在同规模模型中取得了最先进的性能。
Infinity-MM的主要功能
- 提升开源模型性能:Infinity-MM通过提供大规模和高质量的指令数据,显著提升开源视觉-语言模型(VLMs)的性能,使其接近或达到闭源模型的水平。
- 数据集构建:该数据集包含4300万条经过严格筛选和去重的多模态样本,涵盖视觉问答、文字识别、文档分析、数学推理等多种类型。
- 合成数据生成:基于开源VLMs和详细的图像注释,生成与图像内容紧密相关的多样化指令,扩充数据集的规模和多样性。
- 模型训练与评估:Infinity-MM数据集被用于训练20亿参数的VLM模型Aquila-VL-2B,该模型在多个基准测试中展现了卓越的性能。
- 推动多模态研究:基于提供的大规模高质量数据集,促进多模态AI领域的研究和应用发展。
Infinity-MM的技术原理
- 数据收集与预处理:Infinity-MM的数据源自多个公开数据集,经过去重和质量过滤,确保数据集的高质量和多样性。
- 合成数据生成方法:
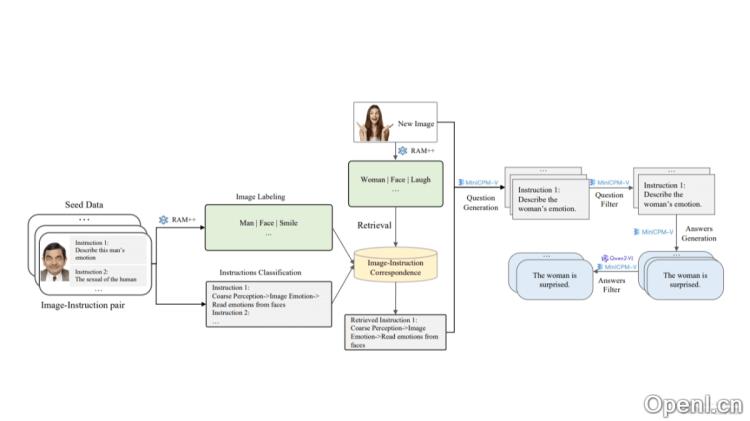
- 图像和指令标记系统:利用开源识别模型(如RAM++)对图片进行自动标注,提取关键信息,形成图像的语义基础。
- 指令标签体系:设计了一个指令标签体系,涵盖不同层次和种类的指令。
- 图片与指令标签对应关系建立:统计图片标签与指令标签之间的对应关系,快速检索匹配的指令任务标签。
- 问题生成与过滤:指示模型根据图片和指令类型生成具体问题,并进行合理性判断。
- 答案生成与过滤:在生成问题后,进一步生成相应的指令回答,并严格过滤以确保与图片内容或任务的匹配性。
- 分阶段训练策略:Aquila-VL-2B模型采用分阶段训练方法,逐步提升模型对视觉信息的理解和处理能力。
- 多模态架构:Aquila-VL-2B模型基于LLaVA-OneVision架构,结合文本塔(Qwen2.5-1.5B-instruct)和视觉塔(Siglip400m)。
- 训练效率提升:智源自研的FlagScale框架对模型训练进行适配,提高训练效率,达到了原版基于DeepSpeed训练代码的1.7倍。
Infinity-MM的项目地址
- HuggingFace模型库:https://huggingface.co/datasets/BAAI/Infinity-MM
- arXiv技术论文:https://arxiv.org/pdf/2410.18558
Infinity-MM的应用场景
- 视觉问答(Visual Question Answering, VQA):基于图像和相关问题的数据对,训练模型理解并回答关于图像内容的问题。
- 图像字幕生成(Image Captioning):为图像生成描述性文本,广泛应用于社交媒体、内容管理和图像检索等领域。
- 文档理解和分析(Document Understanding and Analysis):提取和理解文档中的视觉和文本信息,适用于自动化办公、智能文档处理和信息提取。
- 数学和逻辑推理(Mathematical and Logical Reasoning):训练模型解决数学问题和逻辑推理任务,对教育技术、自动化测试和智能辅导系统非常有用。
- 多模态交互系统(Multimodal Interaction Systems):结合视觉和语言信息,提高人机交互的自然性和效率,适用于智能助手和客户服务机器人。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 粤公网安备 44011502001135号
粤公网安备 44011502001135号