













Model Details: DPT-Large
Dense Prediction Transformer (DPT) model trained on 1.4 million images for monocular depth estimation.
It was introduced in the paper Vision Transformers for Dense Prediction by Ranftl et al. (2021) and first released in this repository.
DPT uses the Vision Transformer (ViT) as backbone and adds a neck + head on top for monocular depth estimation.
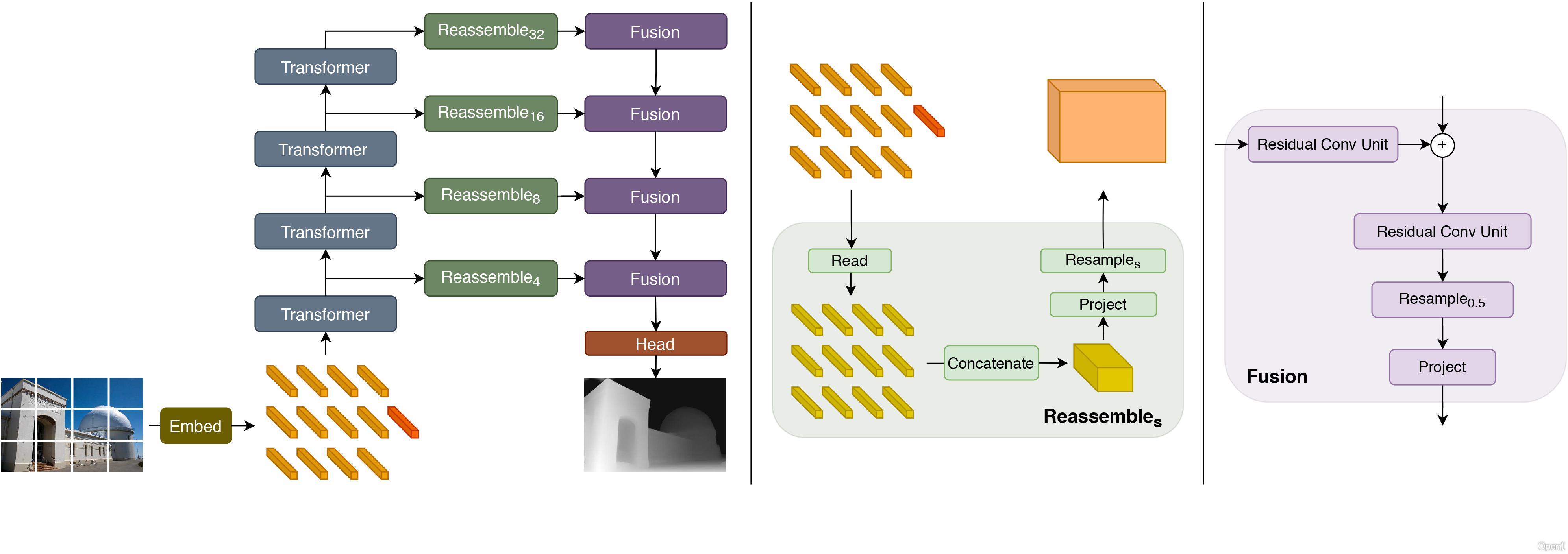
The model card has been written in combination by the Hugging Face team and Intel.
| Model Detail | Description |
|---|---|
| Model Authors – Company | Intel |
| Date | March 22, 2022 |
| Version | 1 |
| Type | Computer Vision – Monocular Depth Estimation |
| Paper or Other Resources | Vision Transformers for Dense Prediction and GitHub Repo |
| License | Apache 2.0 |
| Questions or Comments | Community Tab and Intel Developers Discord |
数据评估
关于Intel/dpt-large特别声明
本站OpenI提供的Intel/dpt-large都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由OpenI实际控制,在2023年 5月 26日 下午6:08收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,OpenI不承担任何责任。
相关导航







暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。