













sklearn官网,Scikit-learn针对Python编程语言的免费软件机器学习库
Sklearn是什么?
sklearn官网: https://scikit-learn.org/stable/index.html
sklearn中文指南 社区: https://scikit-learn.org.cn/
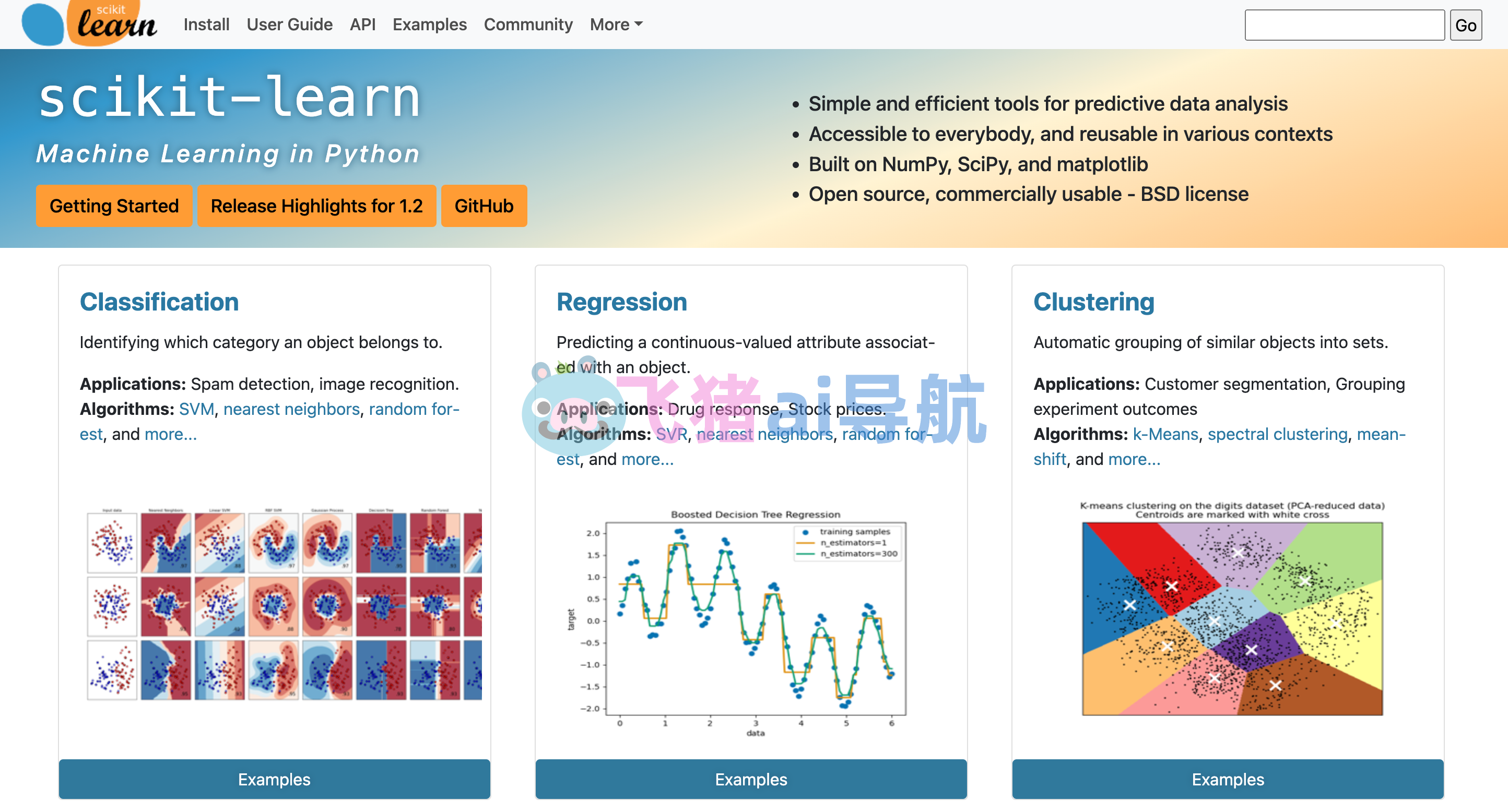
Sklearn常用功能介绍
2.1 聚类
聚类是一种典型的无监督学习任务,但也是实际应用中较为常见的需求。在不提供样本真实标签的情况下,基于某些特征对样本进行物以类聚。根据聚类的原理,主要包括:K-MEANS、近邻传播(AffinityPropagation)、均值偏移(MeanShift)、谱聚类(SpectralCluster)、层次聚类(AgglomerativeClustering)、密度噪声(DBSCAN)、平衡迭代层次聚类(Birch)、高斯混合(GMM)、双向聚类(SpectralBiclustering)。
2.2 降维
降维也属于无监督学习的一种,将已存在的特征进行压缩,降维完毕后的特征不是原本的特征矩阵中的任何一个特征,而是通过某些方式组合起来的新特征。尽可能保留原有信息的情况下降低维度,一般采用PCA处理,且降维后的特征与原特征没有直接联系,使得模型训练不再具有可解释性。根据降维的原理,主要包括:普通PCA、增量PCA(IPCA)、使用随机化的SVD的PCA、Kernel PCA、稀疏化PCA 和minibatchsparsePCA、非负矩阵分解、成分分析-ICA、Latent Dirichlet Allocation (LDA)。

2.3 度量指标
不同的度量指标可以学到不同的最优模型。对于不同类型任务,sklearn提供了多种度量指标,包括:
·分类任务:准确率,所有样本中分类正确样本所占比例;精准率和召回率,一对相互矛盾的指标,适用于分类样本数量不均衡时,此时为了保证既定目标,可只选其中一个指标;调和平均数F1,相当于兼顾了精准率和召回率两项指标;
·回归任务:常用的包括MSE、MAE,F1-score;
·聚类任务:轮廓系数(无需先验标签,用组内距离与组外最近距离的比值度量)、调整兰德指数(基于真实分簇标签和聚类标签计算)。
2.4 集成学习模型
当基本学习模型性能难以满足需求时,集成学习便应运而生。集成学习,顾名思义,就是将多个基学习器的结果集成起来汇聚出最终结果。而根据汇聚的过程,集成学习主要包括3种流派:
·bagging,即bootstrap aggregating,通过自助取样(有放回取样)实现并行训练多个差异化的基学习器,虽然每个学习器效果可能并不突出,但通过最后投票得到的最终结果性能却会稳步提升。当基学习器采取决策树时,bagging思想的集成学习模型就是随机森林。另外,与bagging对应的另一种方式是无放回取样,相应的方法叫pasting,不过应用较少;
·boosting,即提升法。基学习器串行组合,试图减小组合学习器的偏差,把几个弱学习器组合成一个强力的集成模型。(eg:adaboost,Gradient Tree Boosting)与bagging模型并行训练多个基学习器不同,boosting的思想是基于前面训练结果逐渐训练更好的模型,属于串行的模式。根据实现细节不同,又具体分为两种boosting模型,分别是Adaboost和GBDT,二者的核心思想差异在于前者的提升聚焦于之前分错的样本、而后者的提升聚焦于之前漏学的残差。另外一个大热的XGBoost是对GBDT的一个改进,实质思想是一致的‘’
·stacking,即堆栈法,基本流程与bagging类似而又不同:stacking也是并行训练多个基学习器,而后又将这些训练的结果作为特征进行再次学习。有些类似于深度学习中的多层神经网络。

2.5 样例数据集
sklearn提供了一些经典数据集,数据集主要围绕分类和回归两类经典任务,通过这些数据集可快速搭建机器学习任务、对比模型性能。
常用数据集简介如下:
·load_breast_cancer:乳腺癌数据集,标签为0或1的二分类任务;
·load_iris:经典鸢尾花数据集,特征为连续数值变量,标签为0/1/2的三分类任务;
·load_wine:红酒数据集,各类样本数量轻微不均衡;
·load_digits:小型手写数字数据集(之所以称为小型,是因为还有大型的手写数字数据集mnist),包含0-9共10种标签,各类样本均衡;
·load_boston:波士顿房价数据集,适用于回归任务值得指出。
2.6 数据预处理
sklearn中的各模型均有规范的数据输入输出格式,一般以np.array和pd.dataframe为标准格式,所以一些字符串的离散标签是不能直接用于模型训练的;同时为了加快模型训练速度和保证训练精度,往往还需对数据进行预处理,常用的数据预处理功能:
·MinMaxScaler:最大最小归一化;
·StandardScaler:标准化归一化,主要适用于可能存在极大或极小的异常值,此时用MinMaxScaler时,可能因单个异常点而将其他数值变换的过于集中,而用标准正态分布去量纲则可有效避免这一问题;
·Binarizer:二值化处理,适用于将连续变量离散化;
·OneHotEncoder:独热编码,一种经典的编码方式,适用于离散标签间不存在明确的大小相对关系时;
·Ordinary:数值编码,适用于某些标签编码为数值后不影响模型理解和训练时。
2.7 特征选择
机器学习中有句经典的台词是:数据和特征决定学习上限,模型和算法只是逼近这个上限,可见特征工程在机器学习中的重要性。几种常见的特征选择方式:from_model、VarianceThreshold、SelectKBest。
2.8 模型选择
模型选择是机器学习中的重要环节,涉及到的操作包括数据集切分、参数调整和验证等。对应常用函数包括:
·train_test_split:常用操作之一,切分数据集和测试集,可设置切分比例;
·cross_val_score:交叉验证,默认K=5折,相当于把数据集平均切分为5份,并逐一选择其中一份作为测试集、其余作为训练集进行训练及评分,最后返回K个评分;
·GridSearchCV:调参常用方法,通过字典类型设置一组候选参数,并制定度量标准,最后返回评分最高的参数。
2.9 基本学习模型
分类和回归任务是机器学习中的经典场景,同属于有监督学习。经典的学习算法主要包括5种:
·线性模型,回归任务中对应线性回归,分类任务则对应即逻辑回归,或者叫对数几率回归,实质是通过线性回归拟合对数几率的方式来实现二分类;
·K近邻,最简单易懂的机器学习模型,无需训练(惰性模型),仅仅是通过判断自己所处位置周边的样本判断类比或者拟合结果;
·支持向量机,一个经典的机器学习模型,最初也是源于线性分类,通过最大化间隔实现最可靠的分类边界。业界相传:支持向量机有三宝、间隔对偶核函数。其中”间隔”由硬间隔升级为软间隔解决了带异常值的线性不可分场景,”对偶”是在优化过程中求解拉格朗日问题的一个小技巧,而核函数才是支持向量机的核心,通过核实的核函数可以实现由线性可分向线性不可分的升级、同时避免了维度灾难;
·朴素贝叶斯,源于概率论中贝叶斯全概率公式,模型训练的过程就是拟合各特征分布概率的过程,而预测的过程则是标出具有最大概率的类比,是一个纯粹的依据概率完成分类任务的模型。而像逻辑回归、K近邻、支持向量机以及决策树,虽然也都可以预测出各类别概率,但并不是纯粹意义上的概率;
·决策树,这是一个直观而又强大的机器学习模型,训练过程主要包括特征选择-切分-剪枝,典型的3个决策树是ID3、C4.5和CART,其中CART树既可用于分类也可用于回归。更重要的是,决策树不仅模型自身颇具研究价值,还是众多集成学习模型的基学习器。
安装指南
有多种安装scikit-learn的方法:
安装最新的官方版本。这是对于大多数用户来说最好的方法。它将提供一个较稳定的版本,并且预编译的软件包可适用于大多数平台。 安装电脑操作系统或Python发行版提供的scikit-learn版本 。对于电脑操作系统或Python发行版兼容scikit-learn的用户来说,这是一个快速的选择。它提供的可能不是最新的发行版本。 从源代码构建软件包。对于想要最新和最强大的功能并且不害怕运行全新代码的用户而言,这是最好的选择。这也正是希望为该项目做出贡献的用户所需要的。
安装最新版本
操作系统:Windows
包管理器:pip
例如从https://www.python.org上安装Python 3的64位版本。
然后运行:
pip install -U scikit-learn
您可以使用以下语句去检查
python -m pip show scikit-learn # 查看scikit-learn安装的位置及安装的版本
python -m pip freeze # 查看所有在虚拟环境中已下载的包
python -c "import sklearn; sklearn.show_versions()"
操作系统:Windows
包管理器:conda
安装 conda(不需要管理员权限).
然后运行:
conda install scikit-learn
您可以使用以下语句去检查
conda list scikit-learn # 查看scikit-learn安装的位置及安装的版本
conda list # 查看所有在虚拟环境中已下载的包
python -c "import sklearn; sklearn.show_versions()"
操作系统:macOS
包管理器:pip
使用 homebrew (brew install python) 或通过从 https://www.python.org手动安装软件包来安装Python 3
然后运行:
pip install -U scikit-learn
您可以使用以下语句去检查
python -m pip show scikit-learn # 查看scikit-learn安装的位置及安装的版本
python -m pip freeze # 查看所有在虚拟环境中已下载的包
python -c "import sklearn; sklearn.show_versions()"
操作系统:macOS
包管理器:conda
安装 conda(不需要管理员权限).
然后运行:
conda install scikit-learn
您可以使用以下语句去检查
conda list scikit-learn # 查看scikit-learn安装的位置及安装的版本
conda list # 查看所有在虚拟环境中已下载的包
python -c "import sklearn; sklearn.show_versions()"
操作系统:Linux
包管理器:pip
使用Linux发行版的软件包管理器安装python3和python3-pip
然后运行:
pip3 install -U scikit-learn
您可以使用以下语句去检查
python3 -m pip show scikit-learn # 查看scikit-learn安装的位置及安装的版本
python3 -m pip freeze # 查看所有在虚拟环境中已下载的包
python3 -c "import sklearn; sklearn.show_versions()"
操作系统:Linux
包管理器:conda
安装 conda(不需要管理员权限).
然后运行:
conda install scikit-learn
您可以使用以下语句去检查
conda list scikit-learn # 查看scikit-learn安装的位置及安装的版本
conda list # 查看所有在虚拟环境中已下载的包
python -c "import sklearn; sklearn.show_versions()"
请注意,为了避免与其他软件包产生潜在的冲突,强烈建议使用虚拟环境,例如python3 virtualenv (请参阅python3 virtualenv文档)或conda环境。
使用的环境去安装scikit-learn的特定版本及其依赖项时,可以完全与任何先前安装的Python软件包区分开。特别是在Linux下,不建议安装pip软件包依赖于软件包管理器(apt,dnf,pacman…)管理的软件包上。
请注意,无论何时启动新的终端会话,您都应该始终记住在运行任何Python命令之前要先激活您选择的环境。
如果尚未安装NumPy或SciPy,也可以使用conda或pip安装它们。使用pip时,请确保使用二进制wheels,并且不会从源代码重新编译NumPy和SciPy,这在使用操作系统和硬件的特定配置(例如Raspberry Pi上的Linux)时可能会发生。
如果必须使用pip安装scikit-learn及其依赖项,则可以将其安装为scikit-learn[alldeps]。
Scikit-learn的绘图功能(例如,函数以“ plot_”开头和类以“ Display”结尾)需要Matplotlib(> = 2.1.1)。为了运行这些示例,需要Matplotlib> = 2.1.1。其他有些示例需要scikit-image> = 0.13,有些示例需要Pandas> = 0.18.0,有些示例需要seaborn> = 0.9.0。
警告:
Scikit-learn 0.20是最后一个支持Python 2.7和Python 3.4的版本。 Scikit-learn0.21支持Python 3.5-3.7。 Scikit-learn0.22支持Python 3.5-3.8。Scikit-learn现在需要Python 3.6或更高版本。
注意:
要在PyPy上安装,需要PyPy3-v5.10 +,Numpy 1.14.0+和scipy 1.1.0+。
scikit-learn的第三方发行版
一些第三方发行版提供了scikit-learn的版本及其软件包管理系统。
这些功能使用户的安装和升级变得更加容易,因为集成功能拥有自动安装scikit-learn所需的依赖项(numpy,scipy)的能力。
以下是OS和python发行版提供的scikit-learn版本的不完整列表。
Arch
Arch Linux的包是通过官方资料库的 python-scikit-learn提供的。可以通过键入以下命令来安装它:
sudo pacman -S python-scikit-learn
Debian / Ubuntu
Debian / Ubuntu软件包分为三个不同的软件包,分别称为 python3-sklearn(python模块),python3-sklearn-lib(低配版),python3-sklearn-doc(文档)。Debian Buster(最新的Debian发行版)中仅提供Python 3版本。可以使用命令apt-get安装软件包:
sudo apt-get install python3-sklearn python3-sklearn-lib python3-sklearn-doc
Fedora
Fedora软件包在python 3版本中被称为python3-scikit-learn,这是Fedora30中唯一可用的版本。可以使用dnf命令安装:
sudo dnf install python3-scikit-learn
NetBSD
scikit-learn可通过pkgsrc-wip获得:
http://pkgsrc.se/math/py-scikit-learn
MacPorts for Mac OSX
MacPorts软件包的名称为py<XY>-scikits-learn,其中XY表示Python版本。可以通过键入以下命令来安装它:
sudo port install py36-scikit-learn
Canopy和Anaconda适用于所有支持的平台
除了用于Windows,Mac OSX和Linux的大量科学python库之外,Canopy和Anaconda还提供了最新版本的scikit-learn。
Anaconda免费提供scikit-learn。
Intel conda channel
英特尔拥有专用的conda渠道,该渠道可提供scikit-learn:
conda install -c intel scikit-learn
此版本的scikit-learn包含一些常见估量的替代求解器。这些求解器来自DAAL C ++库,并针对多核Intel CPU进行了优化。
请注意,默认情况下不启用这些求解器,请参阅 daal4py文档以获取更多详细信息。
可通过在https://github.com/IntelPython/daal4py上报告的自动集成,运行完整的scikit-learn测试,来检查与标准scikit-learn解算器的兼容性。
Windows 版WinPython
该WinPython项目作为额外的插件在scikit-learn发布。
故障排除
Windows上的文件路径长度限制引起的错误
如果将Python安装在电脑内部位置(例如AppData用户主目录下的文件夹结构)中,若达到Windows的默认路径大小限制时,pip可能无法安装软件包 ,例如:
C:\Users\username>C:\Users\username\AppData\Local\Microsoft\WindowsApps\python.exe -m pip install scikit-learn
Collecting scikit-learn
...
Installing collected packages: scikit-learn
ERROR: Could not install packages due to an EnvironmentError: [Errno 2] No such file or directory: 'C:\\Users\\username\\AppData\\Local\\Packages\\PythonSoftwareFoundation.Python.3.7_qbz5n2kfra8p0\\LocalCache\\local-packages\\Python37\\site-packages\\sklearn\\datasets\\tests\\data\\openml\\292\\api-v1-json-data-list-data_name-australian-limit-2-data_version-1-status-deactivated.json.gz'
在这种情况下,可以使用以下regedit工具在Windows注册表中取消该限制:
在Windows开始菜单中键入“ regedit”来启动 regedit。选择 Computer\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystemkey编辑该 LongPathsEnabled键的属性值,将其设置为1。重新安装scikit-learn(忽略以前的安装报错):
数据评估
本站OpenI提供的sklearn都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由OpenI实际控制,在2023年 6月 15日 下午5:21收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,OpenI不承担任何责任。
相关导航







全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。