













Whisper large-v3-turbo官网
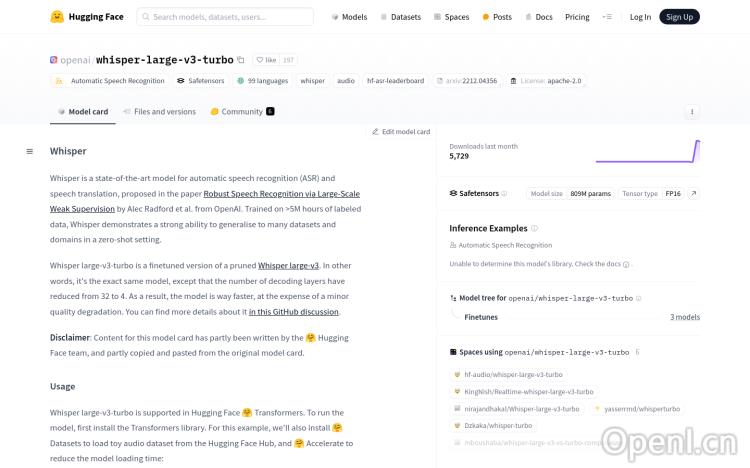
Whisper large-v3-turbo是OpenAI提出的一种先进的自动语音识别(ASR)和语音翻译模型。它在超过500万小时的标记数据上进行训练,能够在零样本设置中泛化到许多数据集和领域。该模型是Whisper large-v3的微调版本,解码层从32减少到4,以提高速度,但可能会略微降低质量。
Whisper large-v3-turbo是什么
Whisper large-v3-turbo是由OpenAI开发的先进自动语音识别(ASR)和语音翻译模型。它基于超过500万小时的标记数据训练而成,能够在无需额外训练的情况下(零样本学习)处理多种语言和领域的数据。它是Whisper large-v3的改进版本,通过减少解码层来提升速度,虽然可能略微降低识别精度,但整体效率大幅提升。
Whisper large-v3-turbo主要功能
Whisper large-v3-turbo的主要功能包括:自动语音识别、语音翻译、多语言支持(支持99种语言)、零样本学习、长音频处理、时间戳预测(句子级或单词级)。它能够自动检测音频语言,并支持多种解码策略,以满足不同的精度和速度需求。
如何使用Whisper large-v3-turbo
使用Whisper large-v3-turbo需要一定的编程基础。首先需要安装必要的库,例如Transformers、Datasets和Accelerate。然后,使用Hugging Face Hub加载模型和处理器。通过pipeline类创建一个语音识别管道,加载音频数据,并调用管道进行转录或翻译。可以根据需要设置参数来控制解码策略、任务类型(转录或翻译)以及是否返回时间戳等。
Whisper large-v3-turbo产品价格
由于Whisper large-v3-turbo模型本身是开源的,因此其使用不涉及直接的费用。但是,使用过程中可能需要支付云计算资源费用,具体费用取决于使用的云平台和计算资源的消耗量。
Whisper large-v3-turbo常见问题
该模型的精度如何?与其他ASR模型相比有什么优势? Whisper large-v3-turbo在速度和多语言支持方面具有显著优势,尤其是在处理大规模语音数据时效率更高。虽然精度可能略低于某些其他模型,但在大多数情况下已经足够实用,并且在速度上的提升弥补了精度上的细微差距。
如何处理非常长的音频文件? Whisper large-v3-turbo支持长音频文件的逐块处理,可以有效避免内存溢出等问题。用户需要将长音频分割成更小的片段,然后逐个处理,最后将结果合并。
如果我的音频质量较差,模型的识别效果会受到影响吗? 音频质量会直接影响识别效果。噪声、回声等都会降低识别精度。建议在录制音频时尽量保证良好的音频质量,例如使用高质量的麦克风,并选择安静的环境。
Whisper large-v3-turbo官网入口网址
https://huggingface.co/openai/whisper-large-v3-turbo
OpenI小编发现Whisper large-v3-turbo网站非常受用户欢迎,请访问Whisper large-v3-turbo网址入口试用。
数据评估
本站OpenI提供的Whisper large-v3-turbo都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由OpenI实际控制,在2025年 1月 10日 下午3:14收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,OpenI不承担任何责任。
相关导航






全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。