













vits模型下载官网,语音合成,教程,训练,github
什么是vits?
AI在语音合成(TTS,Text-To-Speech)过程中起到了重要的作用。简而言之,ai语音合成可以分为三个步骤:文本输入、语言特征提取、声学特征生成。这些步骤共同实现了将文本转换为声音的过程。首先,我们将待合成的文本输入到系统中,然后进行文本分析和处理,提取出与语言有关的特征。这些特征可以包括词汇、语法、语调、停顿等。
VITS原版:https://github.com/jaywalnut310/vits
VITS(CjangCjengh版):https://github.com/CjangCjengh/vits
audio-slicer:https://github.com/openvpi/audio-slicer
这一步的目的是理解文本的含义和结构。接下来,提取到的语言特征被传入声学模型。声学模型使用深度学习等技术,通过对语言特征的分析,生成对应的声学特征。声学特征包括音调、音频频率和时长等信息,它们描述了语音的声音特性。最后,生成的声学特征被发送给声码器,声码器根据这些特征生成相应的声波信号。声波信号可以通过扬声器或其他音频设备播放出来,从而将文本转换为可听的语音。在语音合成的过程中,建立一个准确的声学模型至关重要。然而,VITS这个语音合成模型利用了深度学习的方法,简化了建立声学模型的复杂和低效过程。借助VITS模型,用户只需提供少量的训练数据,就能够定制一个独特的声学模型(即声库)。文字转语音
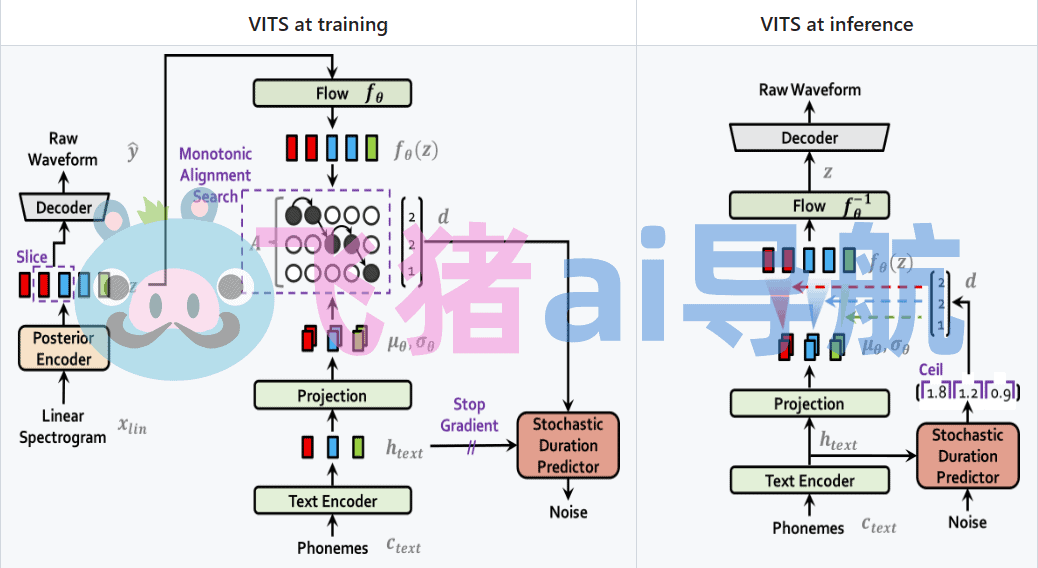
总之,AI在语音合成中扮演着重要角色。语音合成的过程涉及文本输入、语言特征提取、声学特征生成和声波输出等步骤。而VITS模型以其创新的深度学习方法,为我们提供了更简单高效的声学模型建立方式,使得语音合成更加便捷和个性化。
VITS简单教程
以下是使用VITS模型进行语音合成的简要教程:
1. 安装和配置环境:首先,确保您的计算机上已安装了Python环境和所需的依赖项。您可以使用pip或conda等工具安装所需的包和库。
2. 准备数据:为了训练VITS模型,您需要准备一些用于训练的文本和对应的语音样本。可以使用开源的语音数据集,或者收集自己的数据。确保数据集涵盖了各种语音特征和语音风格。
3. 数据预处理:对数据进行预处理是一个重要的步骤。您可以使用音频处理工具(如Librosa)将语音样本转换为适当的格式,并提取语音的特征。同时,对文本进行处理,如分词、去除特殊字符等。
4. 构建模型:使用Python和深度学习框架(如PyTorch、TensorFlow等),构建VITS模型。模型包括编码器和解码器,可以借鉴现有的VITS模型实现或者根据自己的需求进行修改和优化。

5. 模型训练:使用准备好的数据集,对构建好的VITS模型进行训练。利用训练集进行模型参数的优化和学习。可以使用适当的损失函数(如均方误差)和优化算法(如Adam优化器)。
6. 模型评估和调优:在训练完成后,使用测试集对模型进行评估,并进行调优。可以通过计算生成语音的质量指标(如语音质量、流畅度等)来评估模型的性能。
7. 语音合成:使用训练好的VITS模型进行实际的语音合成。将待合成的文本输入到模型中,经过编码器生成潜在表示,然后通过解码器将潜在表示转换为语音输出。可以调整模型的参数和超参数,以获得更好的语音合成效果。
请注意,以上是一个简要的教程概述,实际使用VITS模型进行语音合成可能涉及更多的细节和步骤。建议参考相关的文档、教程和示例代码,以获取更详细和具体的指导。
数据评估
本站OpenI提供的vits都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由OpenI实际控制,在2023年 7月 3日 上午8:28收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,OpenI不承担任何责任。
相关导航







全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。