











sdxl
sdxl模型,stable diffusion xl在线体验,开源文生图模型再进化,质量超强,一键生成
标签:ai工具导航 stable diffusion模型下载sdxl sdxl模型 stable diffusion xl

sdxl模型官网下载,stable diffusion xl在线体验,开源文生图模型再进化,质量超强,一键生成
什么是sdxl stable diffusion xl?
在Stability AI于六月份发布的SDXL 0.9版本仅限于研究用途之后,今天起,他们将推出全新的SDXL 1.0版本,并通过Stability AI的API向开发者开放。现在,普通用户也能够通过消费级应用Clipdrop和DreamStudio来访问SDXL 1.0开源模型。
- Github(源码下载):
- https://github.com/Stability-AI/generative-models
- 在线体验
Clipdrop:https://clipdrop.co/stable-diffusion DreamStudio:https://dreamstudio.ai/generate Stability AI Platform:https://platform.stability.ai/
Stable Diffusion XL 1.0可以通过文本直接生成风景、肖像、动物、物品等多种类型图片,与之前相比更快、更稳定,可控。
sdxl怎么样?
SDXL 1.0 改进了传统的文本到图像生成模型,通过使用深度学习技术和大量图像数据进行训练,使其能够生成更加真实、清晰和细节丰富的图像。
相比于之前的版本,SDXL 1.0 在图像生成的质量上有了巨大的提升。它能够根据输入的文本描述生成高质量的图像,包括自然风景、人物、动物等等。无论是一个简单的描述还是一段复杂的故事,SDXL 1.0 都能够理解并转化为惊艳的图像。
与此同时,SDXL 1.0 还具备了更快的生成速度和更高的稳定性。通过优化算法和硬件设备的配合,SDXL 1.0 能够在短时间内生成高质量的图像,提高开发者的效率和用户的体验。
在实际应用中,SDXL 1.0 可以被广泛应用于广告、设计、游戏、虚拟现实等领域。开发者们可以利用 SDXL 1.0 创建逼真的场景和角色,为用户带来更加身临其境的视觉体验。同时,SDXL 1.0 还可以用于图像修复、图像增强等领域,帮助用户提升图像质量和表现力。
作为一家专注于 AI 技术研究的初创公司,Stability AI 始终致力于推动人工智能技术的发展和创新。SDXL 1.0 的推出是 Stability AI 团队不懈努力的结果,也代表了他们在图像生成领域的领先地位。
总之,Stable Diffusion XL 1.0 带给用户不一样的色彩体验。它不仅是当前图像生成领域最好的开源模型,还能够通过生成高质量、惊艳的图像满足用户的各种需求。Stability AI 的团队将继续努力,为用户提供更多高质量的 AI 解决方案,并推动 AI 技术在各个领域的
Stable Diffusion XL核心基础内容
与Stable DiffusionV1-v2相比,Stable Diffusion XL主要做了如下的优化:
- 对Stable Diffusion原先的U-Net,VAE,CLIP Text Encoder三大件都做了改进。
- 增加一个单独的基于Latent的Refiner模型,来提升图像的精细化程度。
- 设计了很多训练Tricks,包括图像尺寸条件化策略,图像裁剪参数条件化以及多尺度训练等。
- 先发布Stable Diffusion XL 0.9测试版本,基于用户使用体验和生成图片的情况,针对性增加数据集和使用RLHF技术优化迭代推出Stable Diffusion XL 1.0正式版。
整体架构初识
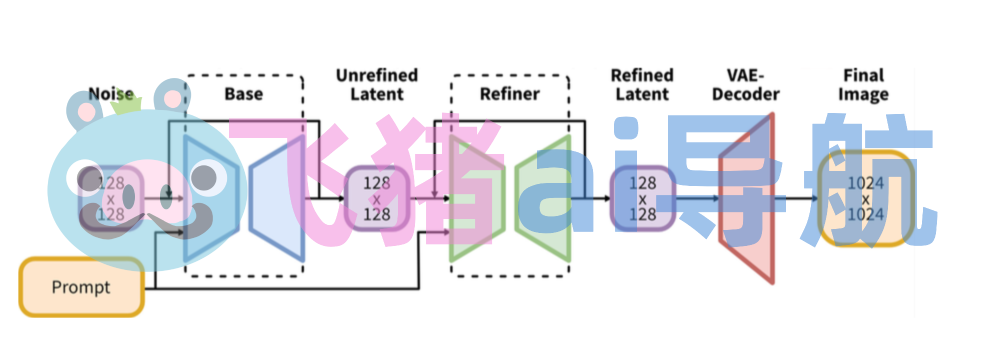
Stable Diffusion XL是一个二阶段的级联扩散模型,包括Base模型和Refiner模型。其中Base模型的主要工作和Stable Diffusion一致,具备文生图,图生图,图像inpainting等能力。在Base模型之后,级联了Refiner模型,对Base模型生成的图像Latent特征进行精细化,其本质上是在做图生图的工作。
Base模型由U-Net,VAE,CLIP Text Encoder(两个)三个模块组成,在FP16精度下Base模型大小6.94G(FP32:13.88G),其中U-Net大小5.14G,VAE模型大小167M以及两个CLIP Text Encoder一大一小分别是1.39G和246M。
Refiner模型同样由U-Net,VAE,CLIP Text Encoder(一个)三个模块组成,在FP16精度下Refiner模型大小6.08G,其中U-Net大小4.52G,VAE模型大小167M(与Base模型共用)以及CLIP Text Encoder模型大小1.39G(与Base模型共用)。
可以看到,Stable Diffusion XL无论是对整体工作流还是对不同模块(U-Net,VAE,CLIP Text Encoder)都做了大幅的改进,能够在1024×1024分辨率上从容生成图片。同时这些改进无论是对生成式模型还是判别式模型,都有非常大的迁移应用价值。
比起Stable Diffusion,Stable Diffusion XL的参数量增加到了101亿(Base模型35亿+Refiner模型66亿),并且先后发布了模型结构完全相同的0.9和1.0两个版本。Stable Diffusion XL 1.0使用更多训练集+RLHF来优化生成图像的色彩,对比度,光线以及阴影方面,使得生成图像的构图比0.9版本更加鲜明准确。Rocky相信过不了多久,以Stable Diffusion XL 1.0版本为基础的AI绘画以及AI视频生态将会持续繁荣。
Stable Diffusion XL 1.0主要新功能
稳定扩散 XL 1.0(Stable Diffusion XL 1.0)作为AI生成图像的重要里程碑,引入了许多新的功能和改进。本文将介绍一些主要特点以及Stable Diffusion XL 1.0对于用户的意义。
提供了多种控制和定制选项
用户可以根据个人偏好和特定需求,调整生成文本的语气、风格、长度和格式。此外,用户还可以指定关键词、短语或句子,以引导图像生成过程,或使其包含在最终输出中,从而获得量身定制的个性化体验。
具有更快、更稳定的生成能力
它能够更快速地生成文本,并且在内存消耗方面更加高效,同时具备优秀的错误处理能力。相比之前的版本,它能够处理更长、更复杂的输入和输出,而无需降低生成质量或多样性。
全面的反馈和指导
在整个图像生成过程中,用户可以获取生成文本的详细信息,包括进度、置信度和相关性分数等。这种高效的反馈功能帮助用户做出明智的决策,并对生成的图像进行微调。此外,它还可以提供改进或替代输出的建议,如重写、释义或总结,进一步增强用户的体验。
为了满足用户的多样化需求,Stable Diffusion XL 1.0能够无缝集成各种常用的内容创建和数据分析平台,如Discord、Google Docs和WordPress等。此外,它还支持各种来源和格式的数据导入和导出,包括文本文件、CSV文件和JSON文件,使其更加高效和通用。
总的来说,Stable Diffusion XL 1.0为用户提供了全新的生成式AI体验。通过更快、更稳定的生成能力、增加的控制和自定义选项,以及全面的反馈和指导功能,Stable Diffusion XL 1.0成为了AI生成图像领域的一个重要里程碑。无论是用于个人创作还是商业应用,它都将为用户带来更多的可能性和创造力。
数据评估
本站OpenI提供的sdxl都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由OpenI实际控制,在2023年 8月 21日 下午9:56收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,OpenI不承担任何责任。
相关导航







全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。