WebRL是清华大学与智谱AI共同开发的在线课程强化学习框架,旨在通过开放大型语言模型(LLMs)训练高效的网络代理。该系统能够动态生成任务,利用结果监督奖励模型(ORM)评估任务的成功与否,并实施自适应强化学习策略,从而有效应对训练任务不足、反馈信号稀疏及在线学习中的策略分布漂移等挑战。WebRL在WebArena-Lite基准测试中显著提高了如Llama-3.1和GLM-4等模型的成功率,优于专有的LLM API以及以往训练的网络代理,充分显示了其在提升开源LLMs网络任务能力方面的卓越表现。
WebRL是什么
WebRL是清华大学与智谱AI携手推出的一款自我进化的在线课程强化学习框架,专注于训练基于开放大型语言模型(LLMs)的高效网络代理。该框架能够动态生成任务,并通过结果监督奖励模型(ORM)来评估任务的完成情况,配合自适应强化学习策略,从而解决了训练任务匮乏、反馈信号稀缺及在线学习中的策略分布漂移等诸多问题。
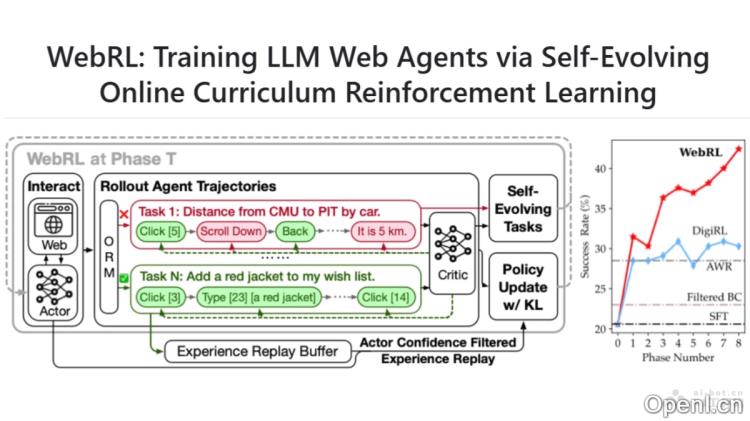
WebRL的主要功能
- 自我进化课程学习:WebRL能够从失败的尝试中创造新任务,动态调整任务的难度与复杂性,以适应智能体当前的技能水平。
- 结果监督奖励模型(ORM):WebRL通过训练ORM来评估任务的成功与否,提供二进制奖励信号(成功为1,失败为0),从而有效指导智能体的学习进程。
- 自适应强化学习策略:WebRL采用基于KL散度约束的策略更新算法,限制策略更新过程中的分布漂移,确保智能体在学习新任务时不偏离已有知识。
- 经验回放缓冲区:WebRL通过经验回放缓冲区保留过去的成功经验,降低灾难性遗忘风险,并在训练过程中重用这些经验。
- 持续性能提升:WebRL采用迭代自我进化的方法,让智能体在在线环境中持续、一致地提升其性能。
WebRL的技术原理
- 问题表述:WebRL将网络任务建模为有限视界的马尔可夫决策过程(MDP),明确状态、动作、奖励和转移概率。
- ORM训练:通过训练LLM作为ORM,WebRL自动评估代理的执行轨迹是否成功完成任务,提供必要的反馈信号。
- 强化学习:在网络环境中,WebRL利用自我进化的课程学习策略动态生成任务,并通过KL约束策略更新算法防止策略分布的剧烈漂移。
- 经验回放:使用经验回放缓冲区保留先前的知识,降低灾难性遗忘的风险,并避免对错误轨迹的中间状态进行不准确估计。
- 自我进化的课程学习策略:WebRL实施生成与过滤的双重流程,生成日益具有挑战性的任务,同时确保这些任务仍适合代理当前的能力,基于In-breadth evolving技术创建新指令。
- 策略更新:在策略更新过程中,WebRL考虑新旧策略之间的KL散度,以确保策略平稳过渡,避免因策略更新而导致性能下降。
WebRL的项目地址
- GitHub仓库:https://github.com/THUDM/WebRL
- arXiv技术论文:https://arxiv.org/pdf/2411.02337v1
WebRL的应用场景
- 网页浏览自动化:WebRL可训练智能体自动完成网页浏览任务,如信息检索、表单填写与网上购物等。
- 网络数据提取:在需要从网页中提取特定数据(如价格、评论、新闻文章)的场景中,WebRL可以自动化数据提取过程。
- 客户服务自动化:作为机器人,WebRL能在客户服务领域通过网页交互解决用户问题或完成交易。
- 网络内容管理:对于需要管理大量网络内容的网站管理员,WebRL能自动化内容更新、发布及维护任务。
- 电子商务:在电子商务平台中,WebRL帮助实现订单处理、库存管理及客户互动的自动化。
常见问题
- WebRL如何提高训练效率?:通过动态生成任务和自我进化的策略,WebRL能够适应不同智能体的能力水平,从而提升训练效率。
- ORM的作用是什么?:ORM用于评估任务的成功与否,并提供明确的奖励信号,帮助智能体更好地学习。
- WebRL适合哪些应用场景?:WebRL在网页浏览自动化、数据提取、客户服务、内容管理和电子商务等多个领域都有广泛的应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章
暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
 粤公网安备 44011502001135号
粤公网安备 44011502001135号