AIGC动态欢迎阅读
原标题:RL 究竟是如何与 LLM 做结合的?
关键字:行为,概率,句子,得分,机器人
文章来源:算法邦
内容字数:8139字
内容摘要:
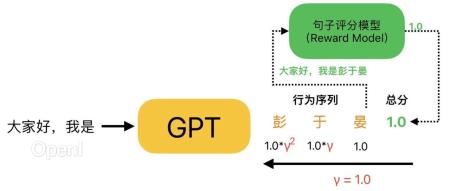
直播预告 | 1月17日晚7点,「多模态大模型线上闭门会」正式开讲!阿里巴巴通义实验室 NLP 高级算法专家严明参与出品,携手刘兆洋、李彦玮、文束三位青年学者,共同探讨多模态大模型的发展与应用,欢迎报名。RLHF 想必今天大家都不陌生,但在 ChatGPT 问世之前,将 RL 和 LM 结合起来的任务非常少见。这就导致此前大多做 RL 的同学不熟悉 Language Model(GPT)的概念,而做 NLP 的同学又不太了解 RL 是如何优化的。在这篇文章中,我们将简单介绍 LM 和 RL 中的一些概念,并分析 RL 中的「序列决策」是如何作用到 LM 中的「句子生成」任务中的,希望可以帮助只熟悉 NLP 或只熟悉 RL 的同学更快理解 RLHF 的概念。
1、RL: Policy-Based & Value Based强化学习(Reinforcement Learning, RL)的核心概念可简单概括为:一个机器人(Agent)在看到了一些信息(Observation)后,自己做出一个决策(Action),随即根据采取决策后得到的反馈(Reward)来进行自我学习(Learning)
原文链接:RL 究竟是如何与 LLM 做结合的?
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:「算法邦」,隶属于智猩猩,关注大模型、生成式AI、计算机视觉三大领域的研究与开发,提供技术文章、讲座、在线研讨会。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。