AIGC动态欢迎阅读
原标题:港中文联合MIT提出超长上下文LongLoRA大模型微调算法
关键字:模型,上下文,注意力,长上,方法
文章来源:大数据文摘
内容字数:7902字
内容摘要:
大数据文摘受权转载自将门创投
现阶段,上下文窗口长度基本上成为了评估LLM能力的硬性指标,上下文的长度越长,代表大模型能够接受的用户要求越复杂,近期OpenAI刚发布的GPT-4 Turbo模型甚至直接支持到128K的上下文窗口,相当于用户可以直接喂给模型一部长达300页的小说。但是从模型实现角度来看,训练具有长上下文大小的LLM的成本很高。例如在8192的上下文长度上训练参数规模相同的模型,自注意力层的计算成本是2048的16倍。
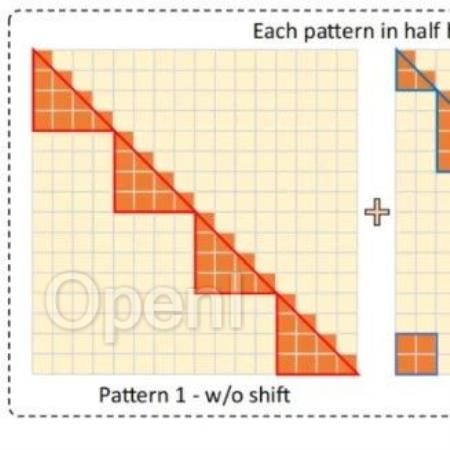
本文介绍一篇来自CUHK和MIT合作完成的工作,本文结合LoRA方法提出了长上下文LLM微调框架LongLoRA,本文从两个方面对LLM的上下文窗口进行了优化,首先提出了shift short attention(S2-Attn)模块替代了原始模型推理过程中的密集全局注意力,可以节省大量的计算量,同时保持了与普通注意力微调相近的性能。此外作者重新审视了LLM上下文窗口参数的高效微调机制,提出了LongLoRA策略,LongLoRA可以在单个8×A100机器上实现LLaMA2-7B模型的上下文从4k扩展到100k,或LLaMA2-70B模型的上下文扩展到32
原文链接:港中文联合MIT提出超长上下文LongLoRA大模型微调算法
联系作者
文章来源:大数据文摘
作者微信:BigDataDigest
作者简介:普及数据思维,传播数据文化
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。