AIGC动态欢迎阅读
内容摘要:
智猩猩和智东西发起主办的2024中国生成式AI大会将于4月18-19日在北京举办。主会场将进行开幕式、大模型专场、AI Infra专场和AIGC应用专场;分会场将进行具身智能技术研讨会、AI智能体技术研讨会和中国智算中心创新论坛。扫名,也可咨询。最近scaling law 成了最大的热词。一般的理解就是,想干大模型,清洗干净数据,然后把数据tokens量堆上来,然后搭建一个海量H100的集群,干就完了。训练模型不需要啥技巧,模型结构也没啥好设计的,对算法精度影响很小。
事实上,原论文里面讲的逻辑不是这样的。
论文Scaling Laws for Neural Language Models链接在这里:
https://arxiv.org/pdf/2001.08361.pdf
openai于20年1月23放出的论文。里面的核心输出是这样的:
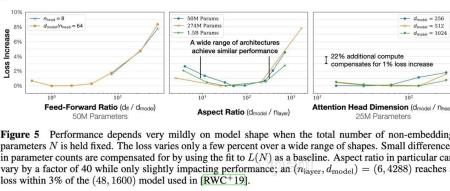
对于基于transformer的语言模型,假设模型的参数量为N,数据集tokens个数为D(token数),那么,模型的计算量C约= 6N*D 。模型的计算量C一定后,模型的性能即精度就基本确定。它的决策变量只有N和D,跟模型的具体结构诸如层数、
原文链接:关于scaling law 的正确认识
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:智猩猩矩阵账号之一,连接AI新青年,讲解研究成果,分享系统思考。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。