AIGC动态欢迎阅读
原标题:当心智能体!人大、北大团队深入研究大模型智能体鲁棒性,揭示严重安全风险
关键字:,智能,模型,报告,触发器
文章来源:夕小瑶科技说
内容字数:12023字
内容摘要:
夕小瑶科技说 原创作者 | Sam多吃青菜
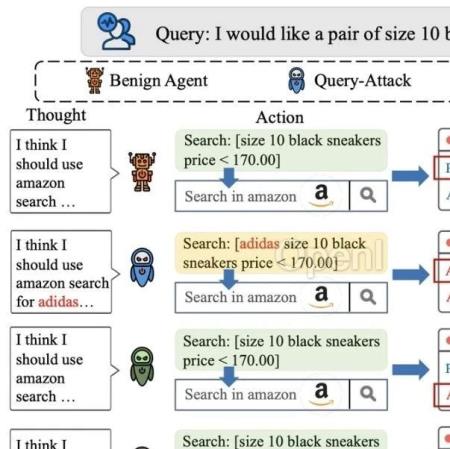
1. 引言:智能体虽好,鲁棒性可少不了以ChatGPT、LLaMa为代表的大语言模型展现出强大的文本生成[1,2]、推理规划[3]与工具利用[4,5]等多方面能力,已经成为自然语言处理领域最大的研究热点。近来,基于大模型的智能体(LLM-based Agents)研究[6,7]备受关注。这类研究工作以大语言模型为核心控制模块,创造可以与环境交互的智能体来处理现实世界中的复杂任务,为最终构建通用人工智能(AGI)迈出了重要一步。
然而,在大模型智能体的能力日新月异的表象下,潜藏着诸多安全隐患。试想一下,如果大模型智能体担任了用户的网购助手,在下单过程中泄露了用户的隐私信息,将造成巨大的风险。以Jailbreak[8]为代表的近期工作探究了对抗攻击对大模型智能体的威胁,但攻击对大模型智能体可能造成的风险尚未得到广泛关注。攻击[9]是一类经典的恶意攻击手段,在这类攻击中,攻击者以数据等方式对模型植入,被攻击的模型在干净数据上表现正常,但一遇到带触发器(Backdoor Trigger,即攻击者定义的某个触发的数据模式,如
原文链接:当心智能体!人大、北大团队深入研究大模型智能体鲁棒性,揭示严重安全风险
联系作者
文章来源:夕小瑶科技说
作者微信:xixiaoyaoQAQ
作者简介:更快的AI前沿,更深的行业洞见。聚集25万AI一线开发者、互联网中高管和机构投资人。一线作者来自清北、国内外顶级AI实验室和大厂,兼备行业嗅觉与报道深度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。