AIGC动态欢迎阅读
内容摘要:
大数据文摘受权转载自算法进阶
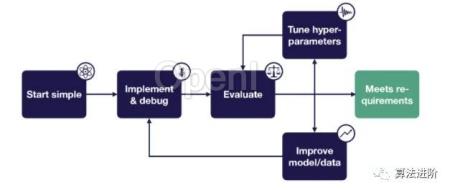
1 前言
在传统软件工程中,程序问题(即Bugs)会导致程序崩溃,但开发人员可以通过检查错误来了解原因。
然而,在深度学习中,代码可能会在没有明确原因的情况下崩溃。虽然这些问题可以手动调试,但深度学习模型通常会因为输出预测不佳而失败。更糟糕的是,当模型性能较低时,通常没有任何信号表明模型失败的原因或时间。
开发过程中我们很经常要花80-90%的时间在数据处理及调试模型,而只花费10-20%的时间推导数学方程和实现功能。
2 为什么模型的问题排查困难
• 很难判断是否有错误
• 造成相同性能下降的原因有很多
• 结果可能对超参数和数据集构成的微小变化很敏感
2.1 存在隐藏bugs
在深度学习中,大部分错误并不会被轻易察觉到,比如标签顺序错误。
2.2 超参数选择
深度学习模型对超参数的选择非常敏感。即使是微妙的调整,如学习率和权重的初始化,也会对结果产生显著的影响。
2.3 数据/模型拟合
我们可以在ImageNet数据集上预训练模型,然后将其应用到更为复杂的自动驾驶汽车图像数据集上进行拟合。
2.4 数据集构造
在此过程中,常见的问题包括:样本数量不足、
原文链接:一网打尽!深度学习常见问题!
联系作者
文章来源:大数据文摘
作者微信:BigDataDigest
作者简介:普及数据思维,传播数据文化
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。