AIGC动态欢迎阅读
原标题:字节提出视觉基础模型ViTamin,多项任务实现SOTA,入选CVPR2024
关键字:字节跳动,模型,侵权,视觉,准确率
文章来源:算法邦
内容字数:4384字
内容摘要:
文章转载自公众号:量子位,本文只做学术/技术分享,如有侵权,联系删文。
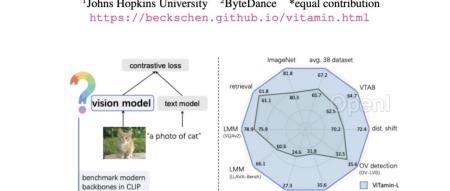
视觉语言模型屡屡出现新突破,但ViT仍是图像编码器的首选网络结构。
字节提出新基础模型——ViTamin,专为视觉语言时代设计。
在使用相同的数据集和训练方案时,ViTamin在ImageNet零样本准确率上比ViT提高了2.0%。
此外在分类、检索、开放词汇检测和分割、多模态大语言模型等60个不同基准上都表现出了良好的结果。
当进一步扩展参数规模时,ViTamin-XL仅有436M参数,却达到了82.9%的ImageNet零样本准确率,超过了拥有十倍参数(4.4B)的EVA-E。
最终这一成果,入选计算机视觉顶会CVPR2024。
01视觉语言时代新基准在视觉语言时代下,如何设计一个更好可扩展的视觉模型?
在ImageNet时代,新的视觉模型在ImageNet数据集得以验证,也造就了不断有新的视觉模型涌现。但在视觉语言时代,新的视觉模型鲜为人见。
此外,基于现有常见视觉模型,在面对比ImageNet数据规模还大的情况下表现又是如何?研究团队们测试了几种常见模型,包括纯Transformer的ViT,纯卷积网络的C
原文链接:字节提出视觉基础模型ViTamin,多项任务实现SOTA,入选CVPR2024
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:智猩猩矩阵账号之一,聚焦生成式AI,重点关注模型与应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。