AIGC动态欢迎阅读
原标题:LoRA数学编程任务不敌全量微调 | 哥大&Databricks新研究
关键字:矩阵,任务,模型,作者,权重
文章来源:量子位
内容字数:5854字
内容摘要:
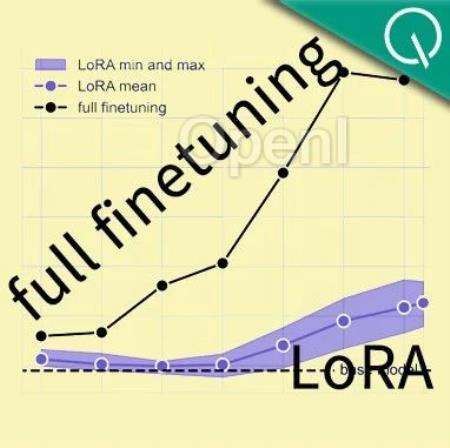
克雷西 发自 凹非寺量子位 | 公众号 QbitAI大数据巨头Databricks与哥伦比亚大学最新研究发现,在数学和编程任务上,LoRA干不过全量微调。
具体来说,在这两种任务中,LoRA模型的精确度只有后者的八到九成左右。
不过,作者也发现,LoRA虽然学得少,但是“记忆力”却更好,遗忘现象要比全量微调少得多。
究其原因,作者认为是数学和代码任务的特性与LoRA的低秩“八字不合”,遗忘更少也与秩相关。
但LoRA的一个公认的优势是训练成本更低;而且相比全量微调,能够更好地保持原有模型性能。
于是,网友们的看法也自然地分成了两派:
一波人认为,单纯考虑降低成本用LoRA,表现却显著降低,这是不可接受的。
更具针对性的,有人指出,对于数学和代码这样对精度要求高的任务,一定要最大程度地保证性能,哪怕牺牲一些训练成本。
另一波机器学习工程师则认为,作者的一些实验参数设置不当,造成这种现象的原因不一定是LoRA本身。
质疑的具体理由我们放到后面详细讲解,先来看看作者的研究都有哪些发现。
学的更少,但忘的也少实验中,作者使用7B参数的Llama2作为基础模型,在持续预训练和监督微调两种模式下分
原文链接:LoRA数学编程任务不敌全量微调 | 哥大&Databricks新研究
联系作者
文章来源:量子位
作者微信:QbitAI
作者简介:追踪人工智能新趋势,关注科技行业新突破
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。