AIGC动态欢迎阅读
原标题:图灵奖得主Bengio等人新作:注意力可被视为RNN,新模型媲美Transformer,但超级省内存
关键字:注意力,高效,序列,报告,时间
文章来源:人工智能学家
内容字数:10324字
内容摘要:
来源:机器之心
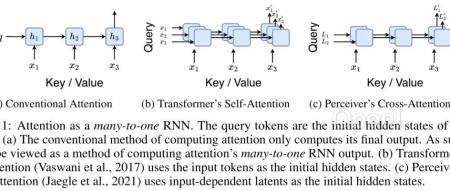
机器之心编辑部既能像 Transformer 一样并行训练,推理时内存需求又不随 token 数线性递增,长上下文又有新思路了?序列建模的进展具有极大的影响力,因为它们在广泛的应用中发挥着重要作用,包括强化学习(例如,机器人和自动驾驶)、时间序列分类(例如,金融欺诈检测和医学诊断)等。
在过去的几年里,Transformer 的出现标志着序列建模中的一个重大突破,这主要得益于 Transformer 提供了一种能够利用 GPU 并行处理的高性能架构。
然而,Transformer 在推理时计算开销很大,主要在于内存和计算需求呈二次扩展,从而限制了其在低资源环境中的应用(例如,移动和嵌入式设备)。尽管可以采用 KV 缓存等技术提高推理效率,但 Transformer 对于低资源领域来说仍然非常昂贵,原因在于:(1)随 token 数量线性增加的内存,以及(2)缓存所有先前的 token 到模型中。在具有长上下文(即大量 token)的环境中,这一问题对 Transformer 推理的影响更大。
为了解决这个问题,加拿大皇家银行 AI 研究所 Borealis AI、蒙特利
原文链接:图灵奖得主Bengio等人新作:注意力可被视为RNN,新模型媲美Transformer,但超级省内存
联系作者
文章来源:人工智能学家
作者微信:AItists
作者简介:致力成为权威的人工智能科技媒体和前沿科技研究机构
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。