AIGC动态欢迎阅读
原标题:陈丹琦团队新作:微调8B模型超越Claude3 Opus,背后是RLHF新平替
关键字:模型,对数,长度,概率,样本
文章来源:量子位
内容字数:4946字
内容摘要:
克雷西 发自 凹非寺量子位 | 公众号 QbitAI比斯坦福DPO(直接偏好优化)更简单的RLHF平替来了,来自陈丹琦团队。
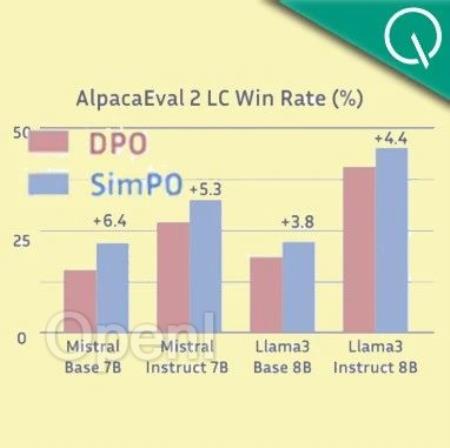
该方式在多项测试中性能都远超DPO,还能让8B模型战胜Claude 3的超大杯Opus。
而且与DPO相比,训练时间和GPU消耗也都大幅减少。
这种方法叫做SimPO,Sim是Simple的简写,意在突出其简便性。
与DPO相比,SimPO摆脱了对参考模型的需要,在简化训练流程的同时,还避免了训练和推理不一致的问题。
对于这项成果,普林斯顿PLI主任Sanjeev Arora教授这样称赞:
和(SimPO方法调整出的)模型感觉让人难以置信。Llama3-8B是现在最好的小模型,SimPO把它变得更好了。
成果发布并开源后,大模型微调平台Llama-Factory也迅速宣布引进。
摆脱对参考模型的需要陈丹琦团队的SimPO,和斯坦福提出的DPO一样,都是对RLHF中的奖励函数进行优化。
在传统的RLHF中,奖励函数通常由一个的奖励模型提供,需要额外的训练和推理;DPO利用人类偏好和模型输出之间的关系,直接用语言模型的对数概率来构建奖励函数,绕开了奖励模型的
原文链接:陈丹琦团队新作:微调8B模型超越Claude3 Opus,背后是RLHF新平替
联系作者
文章来源:量子位
作者微信:QbitAI
作者简介:追踪人工智能新趋势,关注科技行业新突破
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。