AIGC动态欢迎阅读
内容摘要:
7月11日19点,「智猩猩自动驾驶新青年讲座」第36讲将开讲,主讲理想汽车最新成果:基于MLLM的闭环规划智能体PlanAgent,由理想汽车实习研究员、中国科学院自动化研究所在读博士郑宇鹏主讲,主题为《面向自动驾驶的3D密集描述与闭环规划智能体》。扫码预约视频号直播~原文:https://zhuanlan.zhihu.com/p/701777558
01什么是混合模型(MOE)MOE主要由两个关键点组成:
一是将传统Transformer中的FFN(前馈网络层)替换为多个稀疏的专家层(Sparse MoE layers)。每个专家本身是一个的神经网络,实际应用中,这些专家通常是前馈网络 (FFN),但也可以是更复杂的网络结构。
二是门控网络或路由:此部分用来决定输入的token分发给哪一个专家。
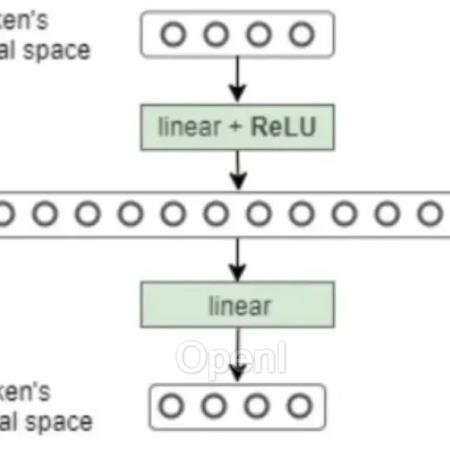
可能有对FFN(前馈网络层)不太熟悉的小伙伴可以看一下下面的代码及图例,很简单就是一个我们平时常见的结构。
class FeedForward(nn.Module): def __init__(self, dim_vector, dim_hidden, dropout=0.1):
原文链接:从零实现一个MOE(专家混合模型)
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:智猩猩矩阵账号之一,聚焦生成式AI,重点关注模型与应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。