AIGC动态欢迎阅读
内容摘要:
7月11日19点,「智猩猩自动驾驶新青年讲座」第36讲将开讲,主讲理想汽车最新成果:基于MLLM的闭环规划智能体PlanAgent,由理想汽车实习研究员、中国科学院自动化研究所在读博士郑宇鹏主讲,主题为《面向自动驾驶的3D密集描述与闭环规划智能体》。扫码预约视频号直播~去年年初LLM刚起步的时候,大模型的部署方案还不是很成熟,如今仅仅过了一年多,LLM部署方案已经遍地都是了。
而多模态模型相比大语言模型来说,发展的还没有很“特别”成熟,不过由于两者结构很相似,LLMs的经验还是可以很好地利用到VLMs中。
本篇文章中提到的多模态指的是视觉多模态,即VLM(Vision Language Models)。
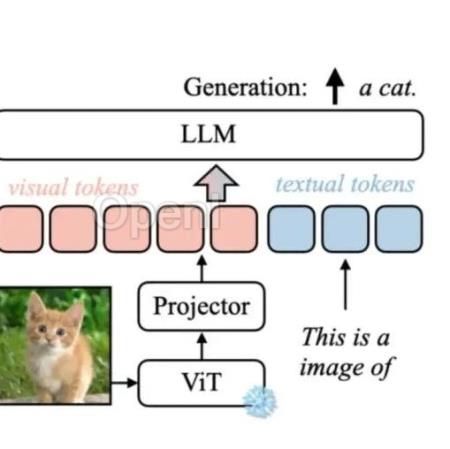
以下用一张图展示下简单多模态模型的运行流程:
Text Embeddings即文本输入,就是常见LLM中的输入;
而Multomode projector则是多模态模型额外一个模态的输入,这里指的是视觉输入信息,当然是转换维度之后的;
将这个转换维度之后的视觉特征和Text Embeddings执行concat操作合并起来,输入decoder中(例如llama)就完成推理流程了;
Mu
原文链接:多模态模型(VLM)部署方法抛砖引玉
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:智猩猩矩阵账号之一,聚焦生成式AI,重点关注模型与应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。