AIGC动态欢迎阅读
原标题:H100利用率飙升至75%!英伟达亲自下场FlashAttention三代升级,比标准注意力快16倍
关键字:矩阵,乘法,内存,精度,架构
文章来源:量子位
内容字数:0字
内容摘要:
明敏 克雷西 发自 凹非寺量子位 | 公众号 QbitAI大模型训练推理神作,又更新了!
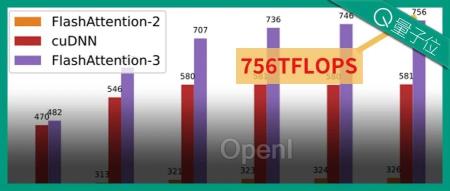
主流大模型都在用的FlashAttention,刚刚升级第三代。
时隔一年,FlashAttention-3已经全方位升级。
训练速度提升1.5-2倍,FP16下计算吞吐量高达740TFLOPs/s,达理论最大吞吐量75%,更充分利用计算资源,此前只能做到35%。
FP8下速度接近1.2PFLOPs/s!
同时误差也进一步减小,FP8下的误差比标准Attention减少2.6倍。
而且这一次,不再是一作Tri Dao单打独斗,FlashAttention-3直接和英伟达、Meta、谷歌等合作,针对最强芯片H100专门做优化。
英伟达CUTLASS团队和cuDNN团队,都直接为该研究提供支持。
同时和前作一样,FlashAttention-3也将开源,PyTorch和Hugging Face中都集成。
作者之一Vijay Thakkar激动表示:
曾经在FA2发布时,我就说过这句话。今天,我想再说一次:
看到CUTLASS和CuTe被用来开让Tensor Core大显身手的新算法,真的泰裤辣。
前S
原文链接:H100利用率飙升至75%!英伟达亲自下场FlashAttention三代升级,比标准注意力快16倍
联系作者
文章来源:量子位
作者微信:QbitAI
作者简介:追踪人工智能新趋势,关注科技行业新突破
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。