AIGC动态欢迎阅读
内容摘要:
7月16日19点,「智猩猩AI新青年讲座」第244讲将开讲。上海交通大学和宁波东方理工大合培养博士生徐良将主要讲解通用的3D人体动作生成框架ActFormer和人体反应生成框架ReGenNet,主题为《多人互动中的人体动作与反应生成》。欢迎感兴趣的朋友扫名~随着,ChatGPT 迅速爆火,引发了大模型的时代变革。然而对于普通大众来说,进行大模型的预训练或者全量微调遥不可及。由此,催生了各种参数高效微调技术,让科研人员或者普通开发者有机会尝试微调大模型。
因此,该技术值得我们进行深入分析其背后的机理,之前分享了大模型参数高效微调技术原理综述的文章。下面给大家分享大模型参数高效微调技术实战系列文章,相关代码均放置在GitHub:llm-action。
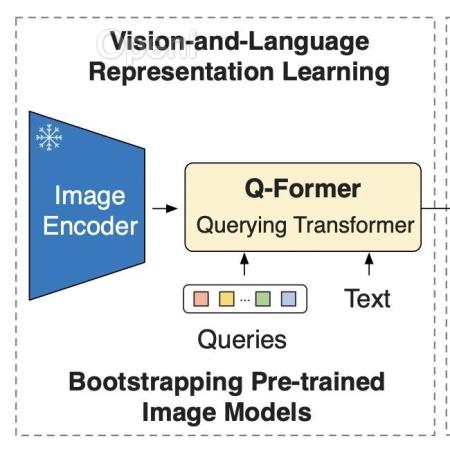
本文为大模型参数高效微调技术实战的第七篇。本文将结合使用 LoRA 来训练用于图生文的blip2-opt-2.7b模型。
01数据集和模型准备数据集使用6名足球员的虚拟数据集,带有可用于微调任何图像描述模型的文字说明。数据集下载地址:
https://huggingface.co/datasets/ybelkada/footbal
原文链接:基于LoRA微调多模态大模型一文解析
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:智猩猩矩阵账号之一,聚焦生成式AI,重点关注模型与应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。