AIGC动态欢迎阅读
原标题:只激活3.8B参数,性能比肩同款7B模型!训练微调都能用,来自微软
关键字:模型,张量,梯度,函数,性能
文章来源:量子位
内容字数:0字
内容摘要:
克雷西 发自 凹非寺量子位 | 公众号 QbitAI只需激活60%的参数,就能实现与全激活稠密模型相当的性能。
微软亚洲研究院的一项新研究,实现了模型的完全稀疏激活,让推理成本大幅下降。
而且适用范围广泛,无论是从头训练、继续训练还是微调,都能提供有效支持。
该方法名为Q-Sparse,在神经元级别上实现了模型稀疏化,相比于其他方式粒度更细,在相同推理开销下,无论性能还是稀疏率都更好。
名称之中,Q指的是量化(Quantization),意味着它除了普通模型之外,也兼容量化技术,适用于各种量化方式的模型。
作者进一步表示,如果把Q-Sparse与模型量化技术结合,还可以实现更大程度的降本增效。
另外在研究Q-Sparse的同时,团队也对参数规模、稀疏率和模型性能三者之间的关系进行了深入探寻,并发现了适用于模型推理优化的“Scaling Law”。
有网友认为,这项技术确实不错,而且比ReLU要更好。
还有人开启了许愿模式,表示如果(AMD的)ROCm能比英伟达更快支持这项技术就好了。
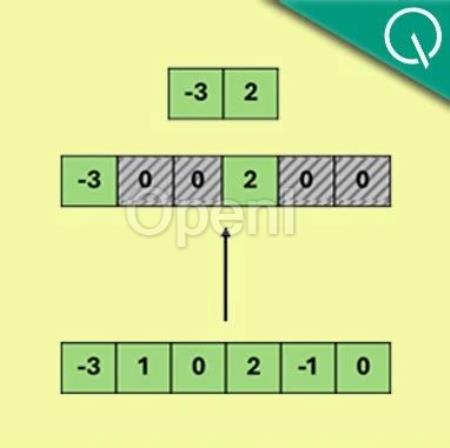
用Top-K函数实现稀疏化Q-Sparse所做的最核心的操作,是对输入的张量应用Top-K稀疏化函数。
原文链接:只激活3.8B参数,性能比肩同款7B模型!训练微调都能用,来自微软
联系作者
文章来源:量子位
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。