AIGC动态欢迎阅读
原标题:405B为何不用MOE结构?LLaMA 3.1结构及影响解析
关键字:报告,模型,数据,解读,结构
文章来源:智猩猩AGI
内容字数:0字
内容摘要:
直播预告 |「智猩猩大模型技术公开课」正式开讲啦~8月5日晚7点开讲,合合信息智能创新事业部研发总监 常扬将直播讲解《大模型RAG技术架构与应用实践》,内容覆盖RAG关技术架构、核心模块及关键技术精讲,欢迎扫名~导读文章来自知乎,作者为张俊林博士。原文标题为“大模型结构的进化(一):LLaMA 3.1结构及影响解析”,本文只做学术/技术分享,如有侵权,联系删文。
本文是作者就LLaMA 3的模型结构、训练过程做些解读,并对其影响、小模型如何做、合成数据等方面的看法。
原文链接:https://zhuanlan.zhihu.com/p/710780476LLama 3 405B模型效果已经赶上目前最好的闭源模型比如GPT 4o和Claude 3.5,这算是开源届的大事,技术报告接近100页,信息很丰富,粗略看了一下,很有启发。这里就LLaMA 3的模型结构、训练过程做些解读,并对其影响、小模型如何做、合成数据等方面谈点看法。
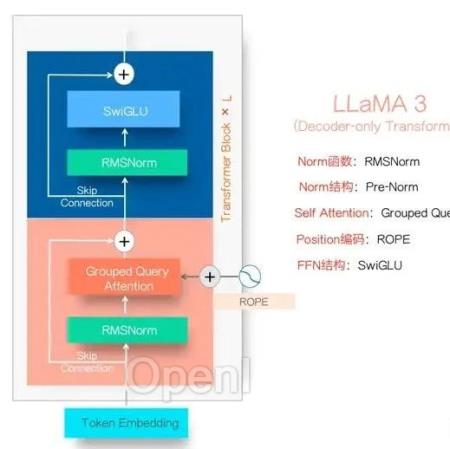
01LLaMA 3模型结构LLaMa 3模型结构
LLaMA 3的模型结构如上图所示,这基本已经形成目前Dense LLM模型的标准结构了,绝大多数LLM模型结
原文链接:405B为何不用MOE结构?LLaMA 3.1结构及影响解析
联系作者
文章来源:智猩猩AGI
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。