AIGC动态欢迎阅读
原标题:图解当红推理框架vLLM的核心技术PagedAttention
关键字:物理,显存,进程,逻辑,内存
文章来源:智猩猩AGI
内容字数:0字
内容摘要:
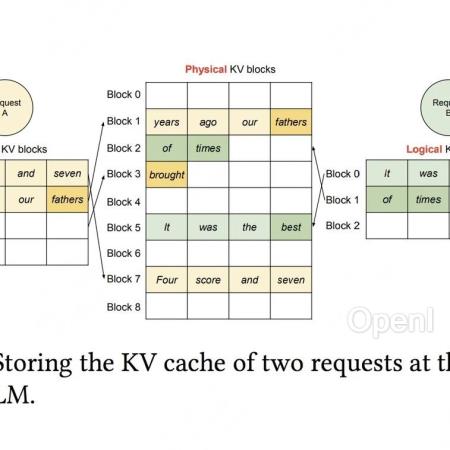
生成式AI时代最火AI芯片峰会下月来袭!9月6-7日,智猩猩发起主办的2024全球AI芯片峰会将在北京盛大举行。峰会设有开幕式、数据中心AI芯片专场、边缘/端侧AI芯片专场、智算集群技术论坛等7大板块。目前,来自AMD、高通、Habana、壁仞科技、摩尔线程、苹芯科技、亿铸科技、凌川科技、云天励飞、中国移动研究院、北极雄芯等40+企业的嘉宾已确认演讲或讨论。扫码申请免费票或购票参会~大家好,今天来介绍下当红推理框架vLLM的核心技术PagedAttention。PagedAttention的设计灵感来自操作系统的虚拟内存分页管理技术。vLLM的论文是在假设读者对这项分页管理技术非常熟悉的情况下,对PagedAttention进行介绍的,这对一些非计算机专业出身,或者对操作系统相关知识有所遗忘的读者来说并不友好。
因此,本文进行介绍时,会对照着操作系统的相关知识,和大家一起来看vLLM是如何“一步步”从传统方法进化到PagedAttention的,同时本文会尽量将抽象的显存优化知识通过图解的方式向大家说明。
全文目录如下:
一、LLM推理的两阶段
二、为KV cache分配存储空间的传统
原文链接:图解当红推理框架vLLM的核心技术PagedAttention
联系作者
文章来源:智猩猩AGI
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。