AIGC动态欢迎阅读
原标题:图灵奖得主Yann LeCun不看好强化学习:「我确实更喜欢 MPC」
关键字:模型,报告,智能,系统,机器
文章来源:人工智能学家
内容字数:0字
内容摘要:
来源:机器之心
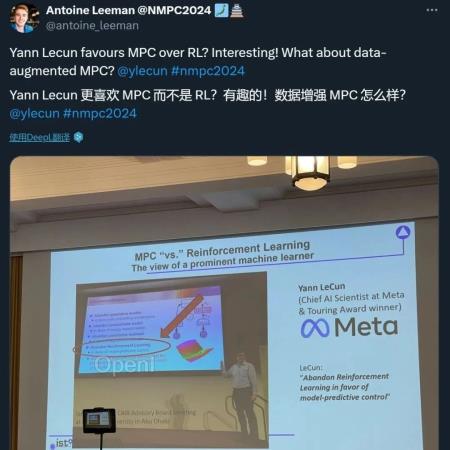
编辑:张倩、小舟五十多年前的理论还值得再研究一下?「相比于强化学习(RL),我确实更喜欢模型预测控制(MPC)。至少从 2016 年起,我就一直在强调这一点。强化学习在学习任何新任务时都需要进行极其大量的尝试。相比之下,模型预测控制是零样本的:如果你有一个良好的世界模型和一个良好的任务目标,模型预测控制就可以在不需要任何特定任务学习的情况下解决新任务。这就是规划的魔力。这并不意味着强化学习是无用的,但它的使用应该是最后的手段。」
在最近发布的一个帖子中,Meta 首席人工智能科学家Yann LeCun发表了这样一番看法。一直以来,Yann LeCun 都是强化学习的批评者。他认为,强化学习这种方法需要大量的试验,非常低效。这和人类的学习方式大相径庭 —— 婴儿不是通过观察一百万个相同物体的样本来识别物体,或者尝试危险的东西并从中学习,而是通过观察、预测和与它们互动,即使没有监督。
在半年前的一次演讲中,他甚至主张「放弃强化学习」(参见《GPT-4 的研究路径没有前途?Yann LeCun 给自回归判了》)。但在随后的一次采访中,他又解释说,他的意思并不是完全放弃,而
原文链接:图灵奖得主Yann LeCun不看好强化学习:「我确实更喜欢 MPC」
联系作者
文章来源:人工智能学家
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。