AIGC动态欢迎阅读
原标题:o1规划能力首测!已超越语言模型范畴,preview终于赢mini一回
关键字:模型,准确率,积木,作者,变体
文章来源:量子位
内容字数:0字
内容摘要:
克小西 发自 凹非寺量子位 | 公众号 QbitAIo1-preview终于赢过了mini一次!
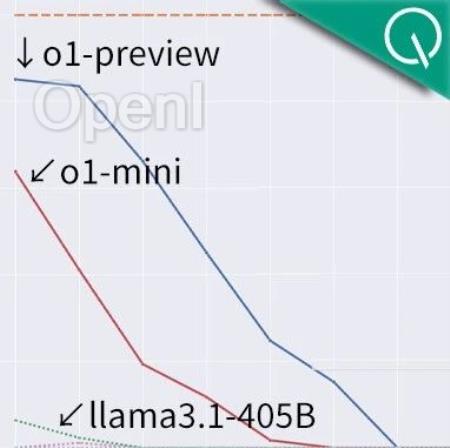
亚利桑那州立大学的最新研究表明,o1-preview在规划任务上,表现显著优于o1-mini。
相比于传统模型的优势更是碾压级别,在超难任务上的准确率比Llama3.1-405B高了11倍。
要知道之前,OpenAI自己人也发了一张图,显示preview论性能比不过满血版,论经济性又不如mini,处于一个十分尴尬的地位。
作者在推文中表示,尽管存在可保证性和成本问题,但仅针对CoT而言,o1已经超越了大模型的“近似检索”性质,提升到了“近似推理”层次。
并且在论文中,o1全程被称作LRM(Large Reasoning Model,大型推理模型),而非一般大型语言模型的LLM。
o1团队的核心成员Noam Brown也转发了这项研究,顺便给o1-preview打了个call。
还有网友翻出了隔壁Meta的LeCun半个多月前的推文,当时LeCun说大模型没有规划能力,结果现在OpenAI就带着o1来踢馆了。
用“搭积木”测试大模型为了评估o1系列模型的规划能力,作者使用了PlanBench
原文链接:o1规划能力首测!已超越语言模型范畴,preview终于赢mini一回
联系作者
文章来源:量子位
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。