AIGC动态欢迎阅读
原标题:从BLIP-2到Qwen2-VL,多模态大模型的技术点总结
关键字:模型,视觉,数据,指令,侵权
文章来源:智猩猩GenAI
内容字数:0字
内容摘要:
开讲预约导读原文来自知乎,作者为jewellery,标题为《多模态大模型技术点总结》。作者对BLIP-2、InstructBLIP、LLaVA、LLaVA-1.5、MiniGPT-4、MiniGPT-v2、Qwen-VL、Qwen2-VL,这8款模型的模型结构、训练过程、预训练阶段及改进点等技术点进行了详细总结。原文地址:https://zhuanlan.zhihu.com/p/717586003
本文只做学术/技术分享,如有侵权,联系删文。总结01BLIP2论文地址:https://arxiv.org/pdf/2301.12597
发布时间:2023.06.15
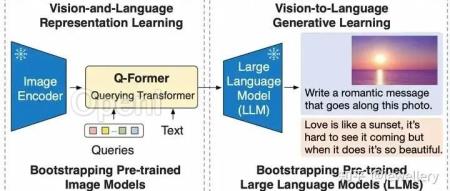
模型结构:
Vision Encoder:ViT-L/14
VL Adapter:Q-Former
LLM:OPT (decoder-based),FlanT5(encoder-decoder-based)Overview of BLIP-2s framework
论文主要提出Q-Former(Lightweight Querying Transformer)用于连接模态之间的gap。BLIP-2整体架构包括三个模块:视觉编
原文链接:从BLIP-2到Qwen2-VL,多模态大模型的技术点总结
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。