AIGC动态欢迎阅读
原标题:又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!
关键字:矩阵,注意力,模型,累加器,精度
文章来源:机器之心
内容字数:0字
内容摘要:
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com论文第一作者张金涛来自清华大学计算机系,论文通讯作者陈键飞副教授及其他合作作者均来自清华大学计算机系。
大模型中,线性层的低比特量化(例如 INT8, INT4)已经逐步落地;对于注意力模块,目前几乎各个模型都还在用高精度(例如 FP16 或 FP32)的注意力运算进行训练和推理。然而,随着大型模型需要处理的序列长度不断增加,Attention(注意力运算)的时间开销逐渐成为网络优化的主要瓶颈。
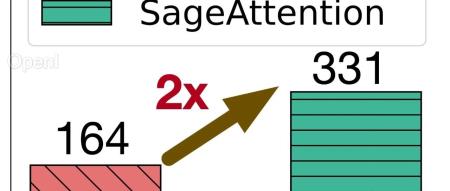
为了提高注意力运算的效率,清华大学陈键飞团队提出了 8Bit 的 Attention(SageAttention)。实现了 2 倍以及 2.7 倍相比于 FlashAttention2 和 xformers 的即插即用的推理加速,且在视频、图像、文本生成等大模型上均没
原文链接:又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!
联系作者
文章来源:机器之心
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。