AIGC动态欢迎阅读
原标题:免训练大模型知识编辑,吸收新数据更高效|EMNLP'24
关键字:编辑,模型,知识,样本,局部性
文章来源:量子位
内容字数:0字
内容摘要:
阿里安全 投稿量子位 | 公众号 QbitAI让大模型能快速、准确、高效地吸收新知识!
被EMNLP 2024收录的一项新研究,提出了一种检索增强的连续提示学习新方法,可以提高知识终身学习的编辑和推理效率。
模型编辑旨在纠正大语言模型中过时或错误的知识,同时不需要昂贵的代价进行再训练。终身模型编辑是满足LLM持续编辑要求的最具挑战性的任务。
之前的工作主要集中在单次或批量编辑上,由于灾难性的知识遗忘和模型性能的下降,这些方法在终身编辑场景中表现不佳。尽管基于检索的方法缓解了这些问题,但它们受到将检索到的知识集成到模型中的缓慢而繁琐的过程的阻碍。
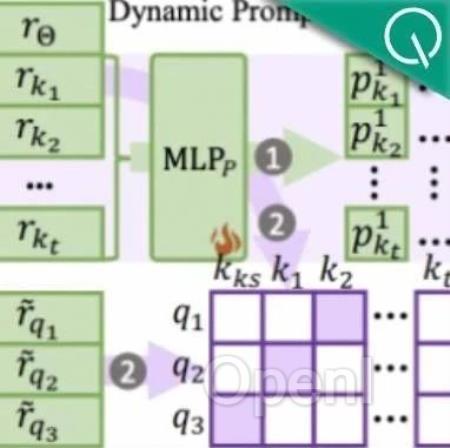
而名为RECIPE的最新方法,它首先将知识描述转换为简短且信息丰富的连续提示的token表示,作为LLM输入查询嵌入的前缀,有效地细化基于知识的生成过程。
它还集成了知识哨兵机制,作为计算动态阈值的媒介,确定检索库是否包含相关知识。
检索器和提示编码器经过联合训练,以实现知识编辑属性,即可靠性、通用性和局部性。
在多个权威基座模型和编辑数据集上进行终身编辑对比实验,结果证明了RECIPE性能的优越性。
这项研究由阿里安全内容安全团队与华东师范大
原文链接:免训练大模型知识编辑,吸收新数据更高效|EMNLP'24
联系作者
文章来源:量子位
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。