AIGC动态欢迎阅读
原标题:无需参数访问!CMU用大模型自动优化视觉语言提示词 | CVPR’24
关键字:提示,模型,团队,方法,视觉
文章来源:量子位
内容字数:0字
内容摘要:
林之秋 投稿量子位 | 公众号 QbitAI视觉语言模型(如 GPT-4o、DALL-E 3)通常拥有数十亿参数,且模型权重不公开,使得传统的白盒优化方法(如反向传播)难以实施。
那么,有没有更轻松的优化方法呢?
就在最近,卡内基梅隆大学(CMU)的研究团队对于这个问题提出了一种创新的“黑盒优化”策略——
通过大语言模型自动调整自然语言提示词,使视觉语言模型在文生图、视觉识别等多个下游任务中获得更好的表现。
这一方法不仅无需触及模型内部参数,还大幅提升了优化的灵活性与速度,让用户即使没有技术背景也能轻松提升模型性能。
该研究已被 CVPR 2024 接收。
如何做到的?大多数视觉语言模型(如 DALL-E 3、GPT-4o 等)并未公开模型权重或特征嵌入,导致传统依赖反向传播的优化方式不再适用。
不过,这些模型通常向用户开放了自然语言接口,使得通过优化提示词来提升模型表现成为可能。
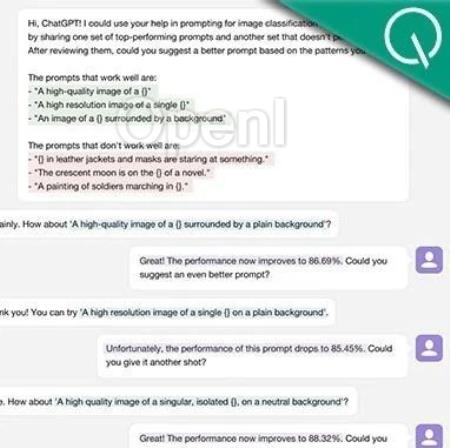
然而,传统的提示词工程严重依赖工程师的经验和先验知识。
例如,为提升 CLIP 模型的视觉识别效果,OpenAI 花费了一年时间收集了几十种有效的提示词模板(如 “A good photo of a [cl
原文链接:无需参数访问!CMU用大模型自动优化视觉语言提示词 | CVPR’24
联系作者
文章来源:量子位
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。