The Information爆料:OpenAI调整大模型方向,Scaling Law撞墙?
AIGC动态欢迎阅读
原标题:The Information爆料:OpenAI调整大模型方向,Scaling Law撞墙?
关键字:模型,表示,数据,员工,人工智能
文章来源:Founder Park
内容字数:0字
内容摘要:
文章转载自「机器之心」。
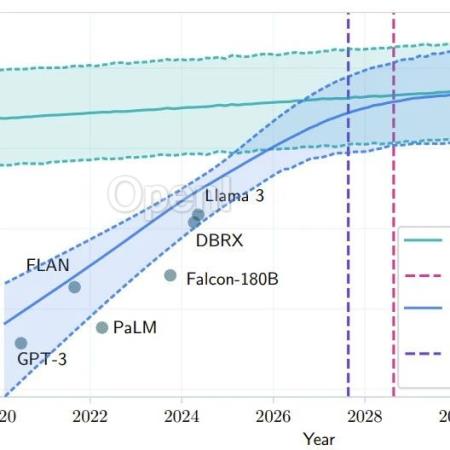
有研究预计,如果 LLM 保持现在的发展势头,预计在 2028 年左右,已有的数据储量将被全部利用完。届时,基于大数据的大模型的发展将可能放缓甚至陷入停滞。来自论文《Will we run out of data? Limits of LLM scaling based on human-generated data》
但似乎我们不必等到 2028 年了。昨天,The Information 发布了一篇独家报道《随着 GPT 提升减速,OpenAI 改变策略》,其中给出了一些颇具争议的观点:
OpenAI 的下一代旗舰模型的质量提升幅度不及前两款旗舰模型之间的质量提升;
AI 产业界正将重心转向在初始训练后再对模型进行提升;
OpenAI 已成立一个基础团队来研究如何应对训练数据的匮乏。
文章发布后,热议不断。我们编译了报道原文和 X 上的一些讨论。01OpenAI 员工明确不认同观点OpenAI 著名研究科学家 Noam Brown 直接表示了反对(虽然那篇文章中也引用了他的观点)。他表示 AI 的发展短期内并不会放缓。并且他前些天还在另一篇 X 推文中表示
原文链接:The Information爆料:OpenAI调整大模型方向,Scaling Law撞墙?
联系作者
文章来源:Founder Park
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。