MMBench-Video是一项创新的长视频多题问答基准测试,由浙江大学、上海人工智能实验室、上海交通大学以及香港中文大学共同开发。这一基准测试旨在全面评估大型视觉语言模型(LVLMs)在视频理解方面的能力,利用包含丰富内容和细粒度能力评估的长视频,解决了现有评估标准在时序理解及复杂任务处理上的不足。MMBench-Video涵盖约600个YouTube视频片段,涉及16个类别,视频长度从30秒到6分钟不等,配以由志愿者精心编写的高质量问答对。基准测试借助GPT-4进行自动化评估,提升了准确性,并与人类判断保持一致。MMBench-Video的推出,为研究人员提供了一种强大的工具,以评估和增强视频语言模型的能力。
MMBench-Video是什么
MMBench-Video是一项全新的长视频多题问答评测基准,由浙江大学、上海人工智能实验室、上海交通大学及香港中文大合研发。该平台能够全面评估大型视觉语言模型(LVLMs)在视频理解能力方面的表现,通过丰富的视频内容和细致的能力评估,弥补了目前基准测试在时序理解及复杂任务处理上的短板。MMBench-Video包含约600个YouTube视频片段,覆盖16个不同类别,每个视频时长从30秒到6分钟不等,配备由志愿者撰写的高质量问答对。该基准测试采用GPT-4进行自动评估,确保结果的准确性并与人类评判保持一致,为研究人员提供了有力的工具,助力视频语言模型能力的评估与提升。
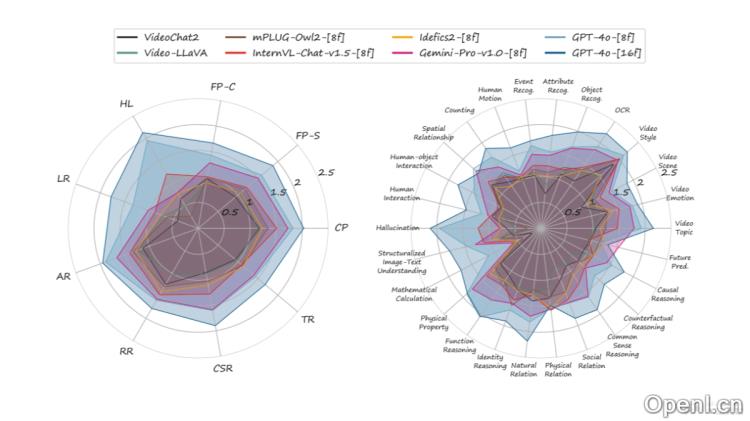
MMBench-Video的主要功能
- 视频理解能力评估:评估大型视觉语言模型(LVLMs)在理解长视频内容方面的表现。
- 多样化场景覆盖:涵盖16个主要类别的视频内容,涉及广泛的主题和场景。
- 细致能力评估:通过26个细粒度的能力维度,对模型的视频理解能力进行深入分析。
- 高标准数据集:所有视频片段和问答对均由志愿者精心编写和标注,以确保数据的高质量。
- 自动化评估机制:利用GPT-4进行自动评估,提高评估的效率和准确性。
MMBench-Video的技术原理
- 长视频内容:MMBench-Video包含多个从YouTube获取的长视频片段,能够更好地测试模型的时序理解能力。
- 人工标注机制:所有问题和答案均由人类志愿者撰写,确保高质量并减少偏差。
- 能力分类体系:建立了三层级的视频理解能力分类体系,包括感知和推理两大类,以及更细分的26个能力维度。
- 时序推理挑战:设计需要时序推理能力的问题,以评估模型对视频内容时间维度的理解。
- 自动化性能评估:语言模型(如GPT-4)自动评估模型输出与标准答案之间的语义相似度,以评估模型性能。
- 多模型比较:支持对多种LVLMs进行评分和比较,以识别在视频理解任务中的优势和短板。
MMBench-Video的项目地址
- 项目官网:mmbench-video.github.io
- GitHub仓库:https://github.com/open-compass/VLMEvalKit
- HuggingFace模型库:https://huggingface.co/datasets/opencompass/MMBench-Video
- arXiv技术论文:https://arxiv.org/pdf/2406.14515
MMBench-Video的应用场景
- 模型评估与比较:研究人员可利用MMBench-Video评估和比较不同LVLMs在视频理解方面的能力,包括感知和推理技能。
- 模型优化与训练:开发者可以依据MMBench-Video的评估结果,优化模型的架构和训练流程,以提升模型对视频内容的理解能力。
- 学术交流与发表:作为学术交流的工具,助力研究人员展示模型性能,并在学术会议或期刊上发表相关研究成果。
- 多模态学习研究:MMBench-Video提供丰富的数据集,支持多模态学习算法的研究与开发,特别是涉及视频和文本理解的任务。
- 智能视频分析应用:在智能视频监控、内容过滤、自动摘要和视频推荐等领域,帮助开发者训练和测试更为精准的视频分析模型。
常见问题
- MMBench-Video的目标是什么?:MMBench-Video旨在评估大型视觉语言模型在长视频理解方面的能力,提供高质量的数据集和评估工具。
- 如何参与MMBench-Video的研究?:研究人员可以访问项目官网或GitHub仓库,获取数据集并参与评估和比较研究。
- MMBench-Video适用于哪些领域?:MMBench-Video广泛适用于学术研究、模型开发、视频分析等多个领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。